
Introduction
Hi all, recently, I observed how chatGPT and other AI bots read my blog. This is good for my SEO since Google ranking is very harsh for small bloggers like me.
Retaining traffic from search engines can be challenging because to rank highly on platforms like Google, we need to optimise our content, comply with their guidelines, post regularly, and compete with other bloggers and larger companies (for instance, Reddit :) often favoured by search engines. This is how the system operates. Whether we use AI or not, small blogs and websites can quickly become invisible to human visitors if they don’t follow these practices.
Using Google Analytics 4 to track ChatGPT traffic can provide insights into how AI chatbots interact with your website and which pages are most valuable to them. As generative AI search evolves, it is crucial to adapt and optimise our content accordingly through effective web analytics.
Google Analytics 4 (GA4) is a robust platform for modern web properties. We will cover the setup process, best practices, and troubleshooting tips to ensure your blog or website accurately tracks and reports on ChatGPT or any other AI usage you would like to track.
What is Google Analytics 4 (GA4)?
Skip this section if you are already using GA4 and have it set up for your project. Otherwise, you can also read my previous post Moving to GA4 about GA4 usage, its features and alternatives.
Google Analytics 4 (GA4) is the latest version of Google’s analytics platform, offering enhanced privacy controls, cross-platform tracking capabilities, and improved performance. It is designed to provide detailed insights into user behaviour, including which pages or features users interact with while browsing your website or using third-party applications.
Why Web Analytics is vital for SEO? Knowing web user behaviour patterns is critical for optimising our websites. With GA4, you can track various aspects of user engagement, including:
- Usage patterns: How long users spend on specific pages or features
- Behavioral data: Which links are clicked or forms are submitted by users
- Performance metrics: Page load times and error rates
Worry about me tracking your clicks? Don't worry, you can easily disable it in my Cookie form in the Performance and Analytics section :)
Setting Up Google Analytics 4 for AI Tracking
Firstly, ensure your project is configured with GA4 installed and operational. To verify the setup, visit Google Analytics 4 Documentation.
1. Create a GA4 Property
The first step in setting up GA4 is creating a new property. You can do this in the Google Analytics. You can read my previous post Moving to GA4 for the complete setup and the GA4 usage patterns. I will repeat the basic GA4 setup here for completeness.
- Go to Google Could Console and log in with your preferred Google credentials.
- Once you have signed in with your Google account, click the [Start measuring] button.
- Next, choose a name for your Google Analytics account. Then, you will see different options for sharing data. Make sure to set these options before clicking Next.
- You will then be guided to create a new Property. Otherwise, the Property menu appears when pressing the “Admin” gear icon on the left bottom side of the screen.
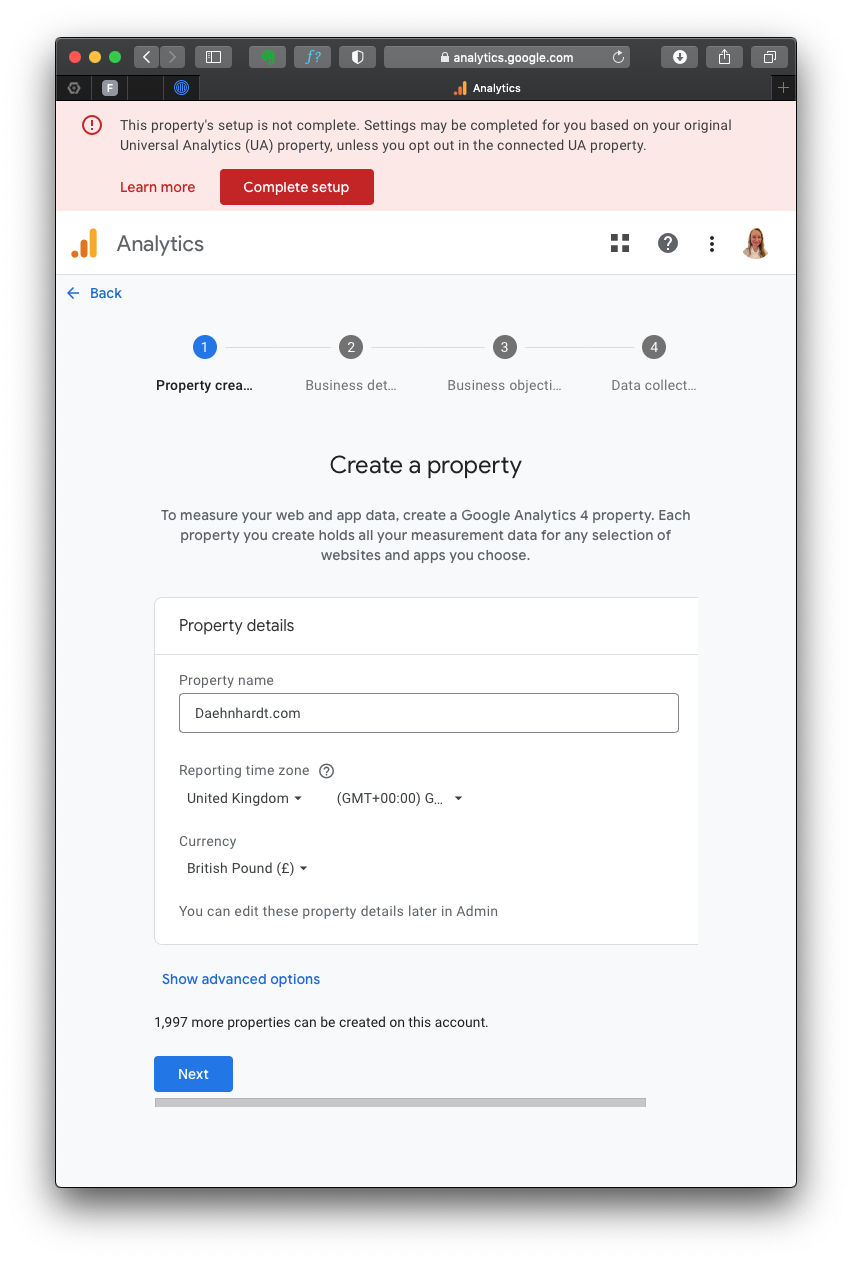
Fill in the required details:
- Property name: Enter your website’s GA4 name;
- Reporting Time Zone: Select your time zone;
- Currency displayed: Choose your currency.
After you press “Next,” you must provide your business details, such as Industry category and Business size. When selecting your business goals, choose the objectives that best fit your needs.
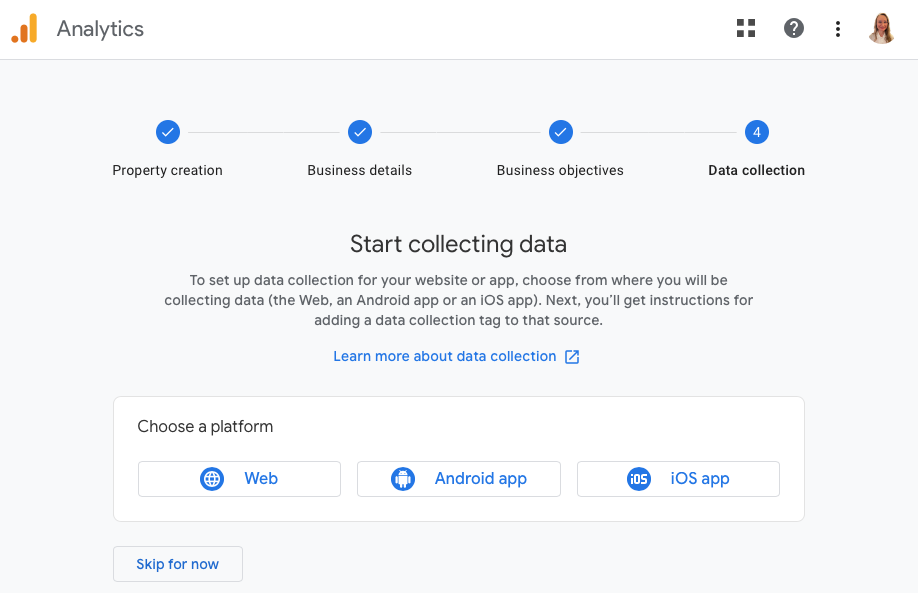
Since I use the GA4 property for my website analytics, I choose “Web” platform.
Now, we will set up a data stream wherein we enter our website’s URL and other required information.
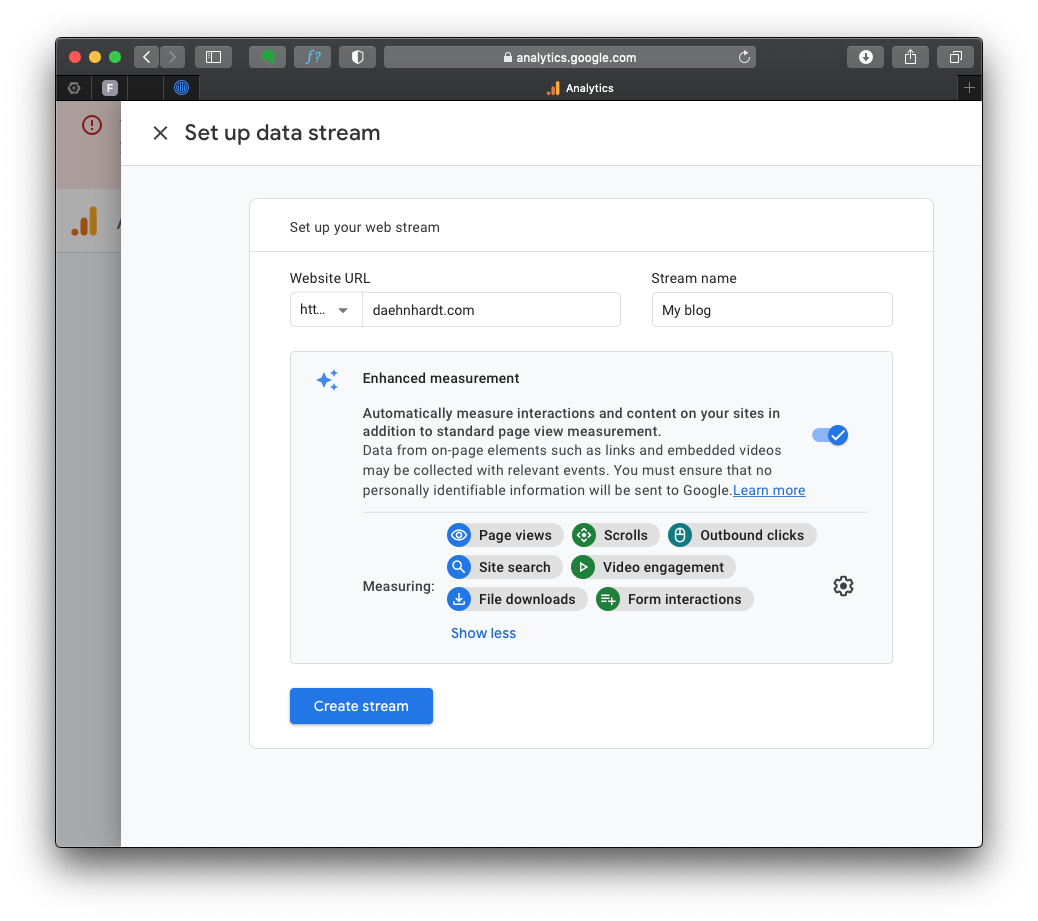
By default, the events with these names will be tracked:
- page_view: page views;
- scroll: page scrolls;
- click: outbound link clicks;
- view_search_results: site searches;
- video_start, video_progress, video_complete: video Engagement;
- file_download: file downloads;
- form_start and form_submit: form submissions;
You can enable or disable these events in the “Enhanced Measurement.”
2. Install GA4 Code
After creating the GA4 property, you’ll see a page with the Measurement ID (starts with “G-“). Copy this ID, as you’ll need it later.
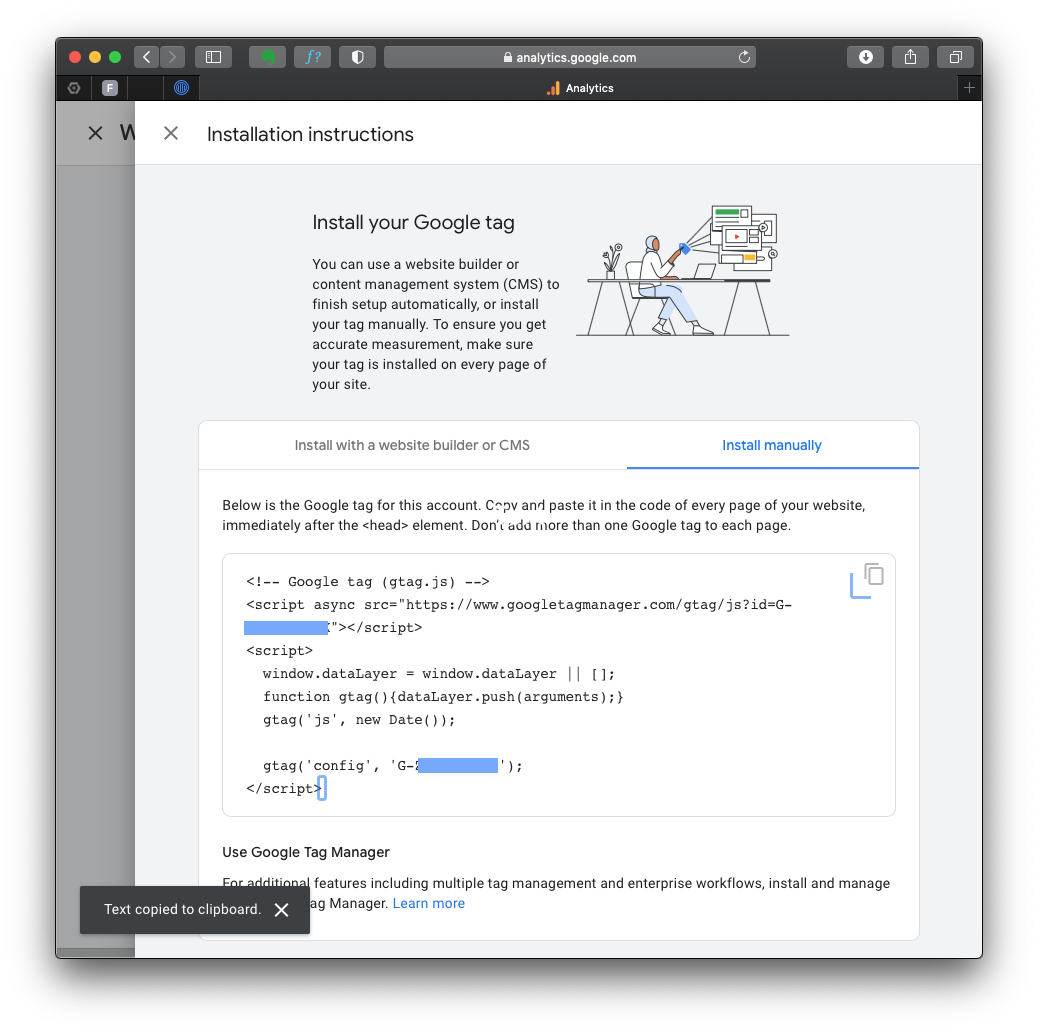
If you lose your tag ID, you can always return to this page, which is in the “Admin” area, in the “Data Streams” section.
The complete GA4 code is in the “Stream details”, “Google Tag” section “View tag instructions”. Notice the green mark “Data Flowing”? That’s because I already have my tag on the HTML page, and it’s receiving data from you just now!
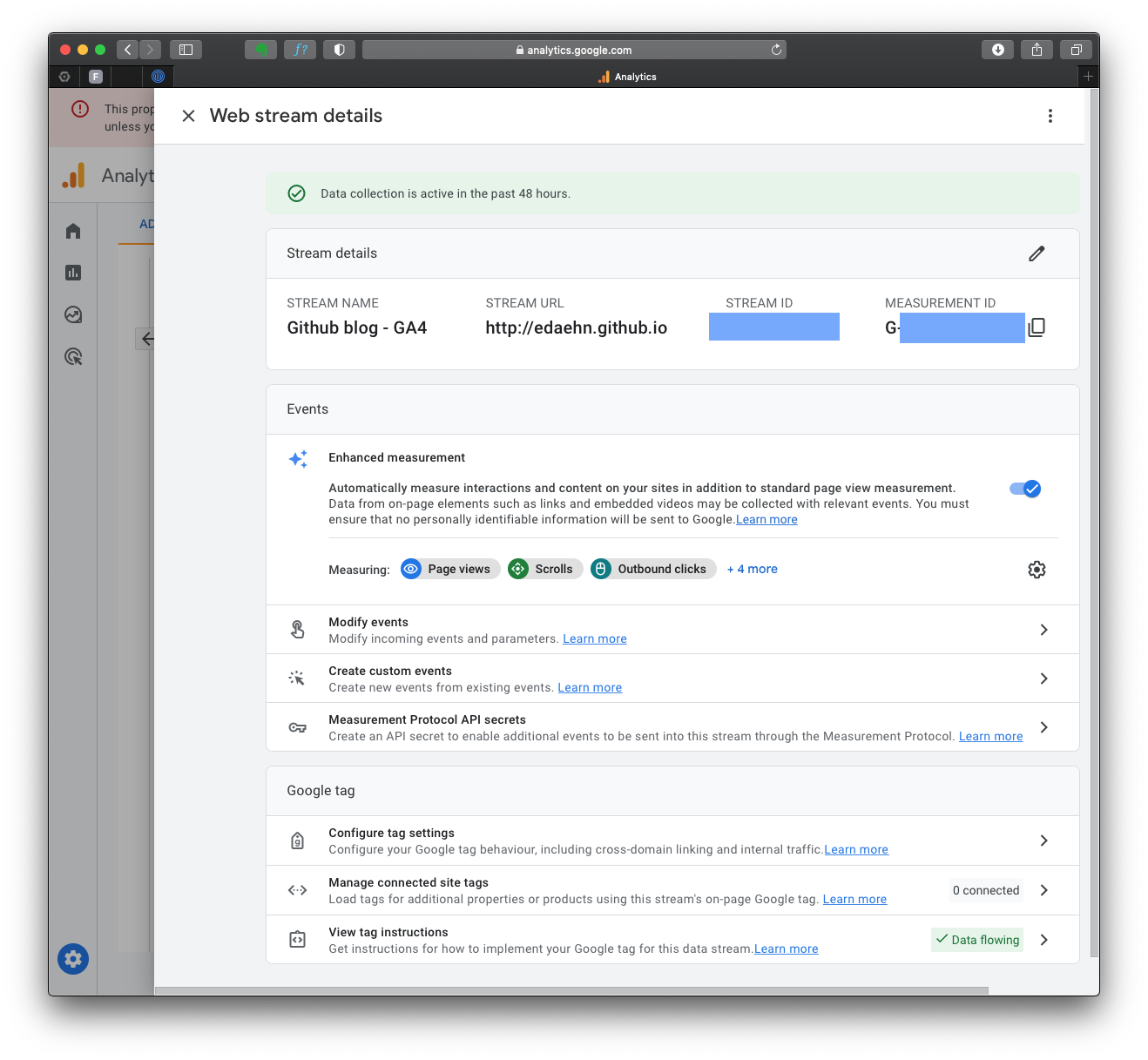
After you click on that section, you can choose the appropriate method to install the GA4 tracking code, depending on your website platform. For instance, if your website is built with HTML, open your website’s HTML page in a text editor. Locate the <head> section of your HTML code.
To start collection data, you should include the following code snippet immediately before the closing </head> tag:
<!-- Global site tag (gtag.js) - Google Analytics -->
<script async src="https://www.googletagmanager.com/gtag/js?id=GA_MEASUREMENT_ID"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'GA_MEASUREMENT_ID');
</script>
You must alter the GA_MEASUREMENT_ID with the Measurement ID you copied before, and of course, save the HTML file and upload it to your website’s server.
When required, complete instructions for website builders at GA4: Set up Analytics for a website and/or app.
2. Tracking ChatGPT Usage
To track ChatGPT traffic, you must ensure that your website pages include a Google Analytics tracking code. This allows GA4 to capture user interactions within the AI framework.
Tracking AI traffic with GA4
Traffic acquisition
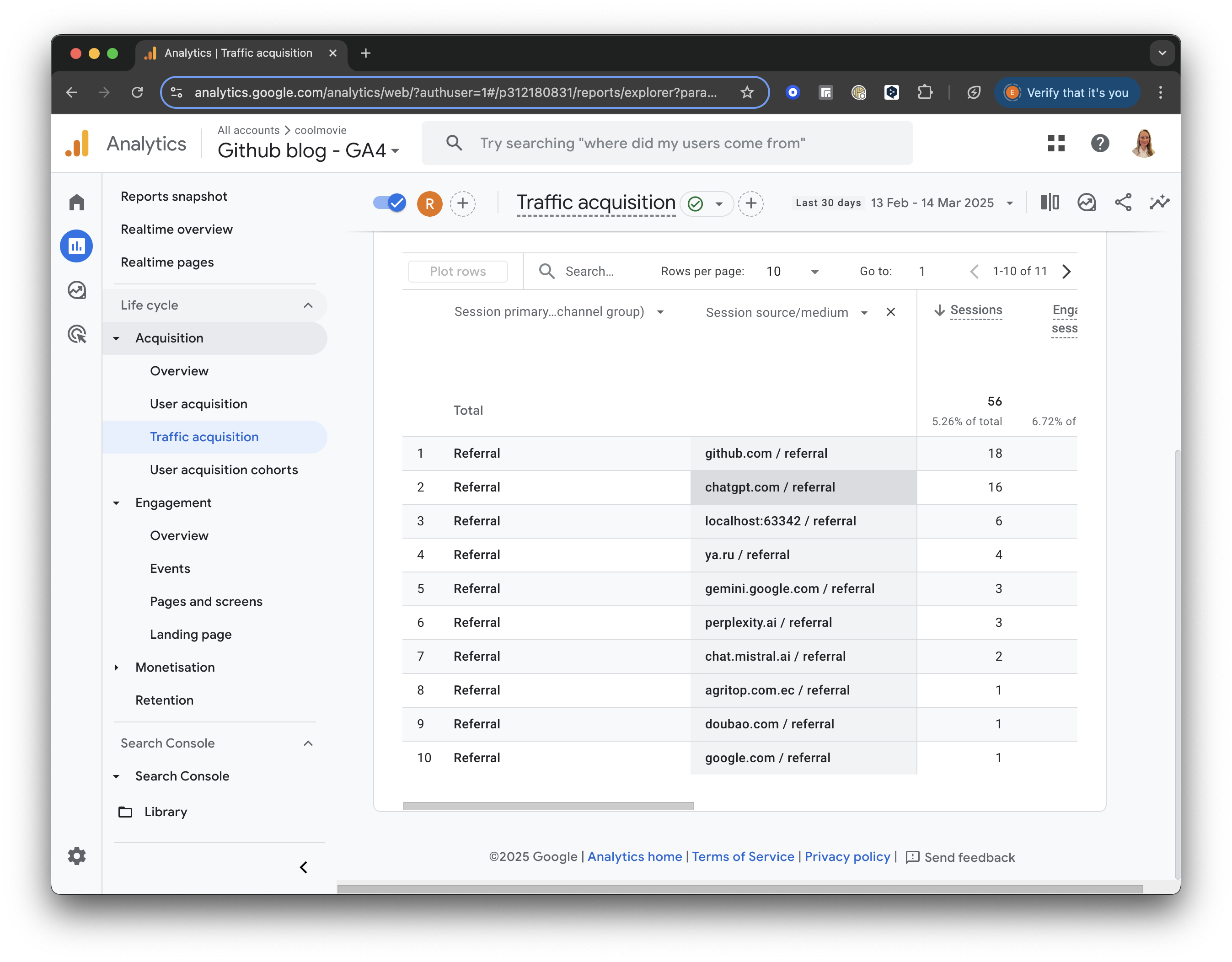
In the left menu, under “Life Cycle,” locate the “Acquisition” section. Click “Acquisition” and choose “Traffic acquisition” from the dropdown list.
The Traffic Acquisition report displays session data by primary channel group, such as Organic Search, Direct, Referral, etc.
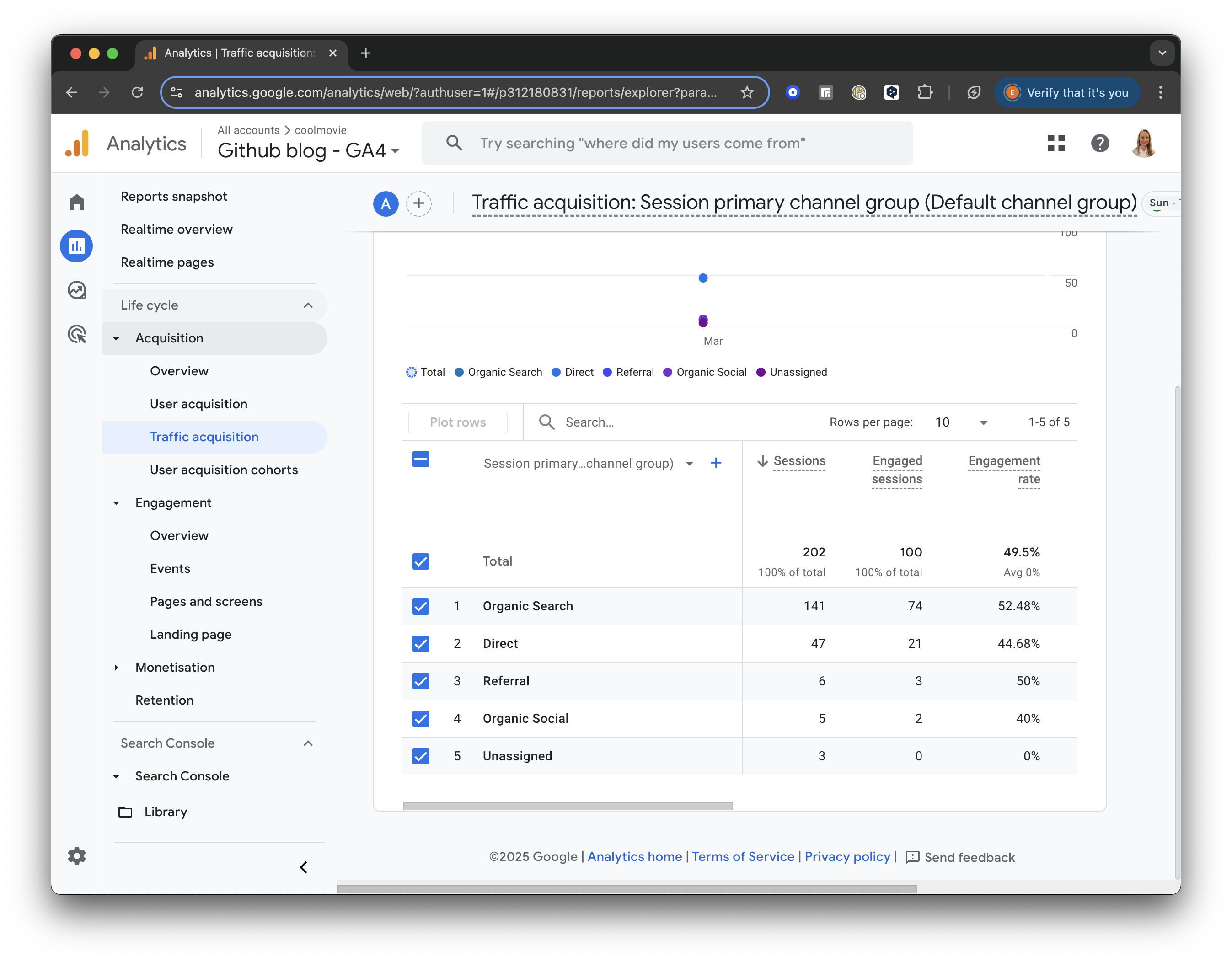
GA4 screenshot: Traffic Acquisition
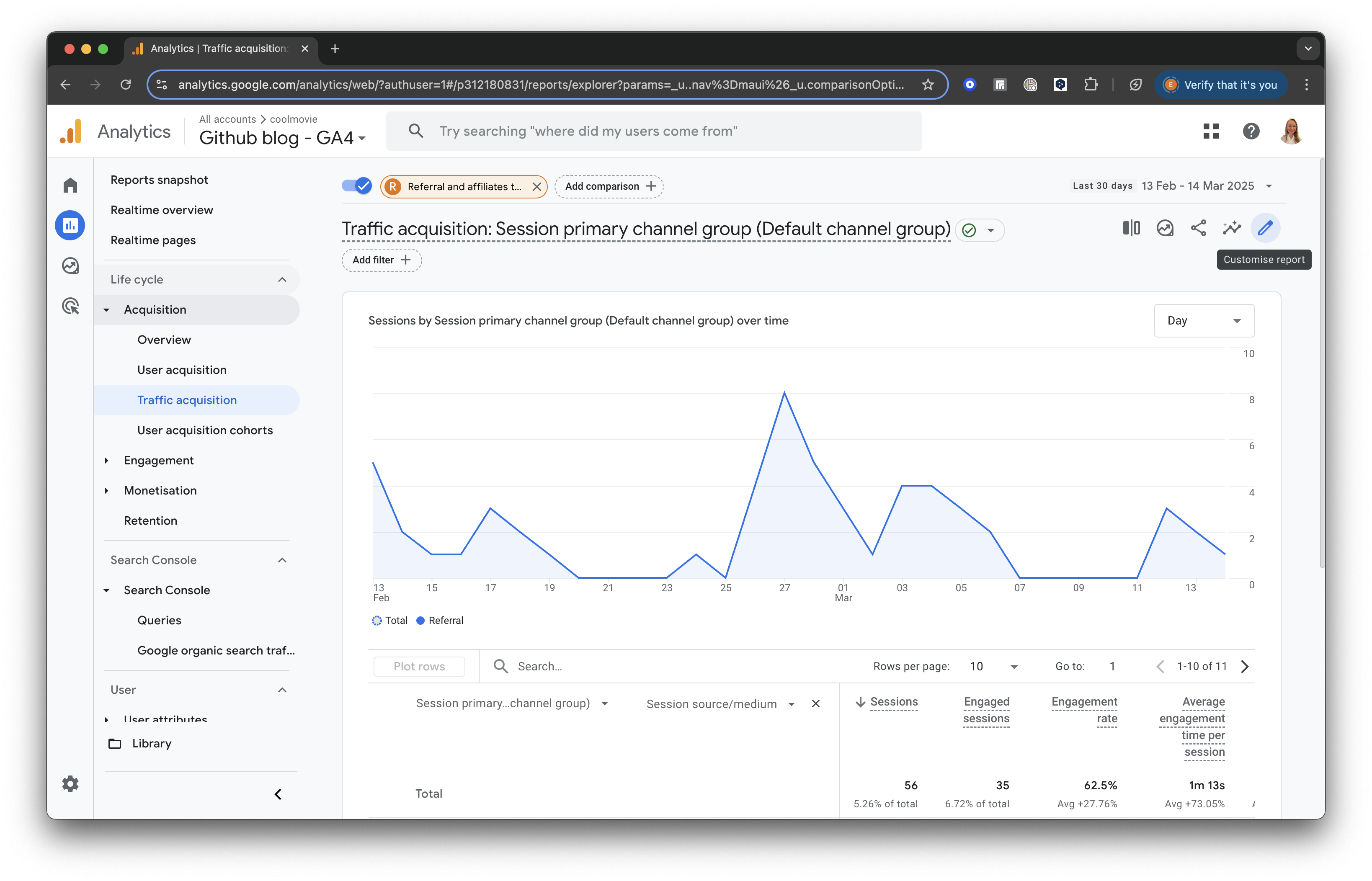
Add Comparison
Click the “Add Comparison” button at the top of the screen. Uncheck the box for “All Users” and scroll down to check the box for “Referral & Affiliates Traffic” to focus only on traffic from referrals.
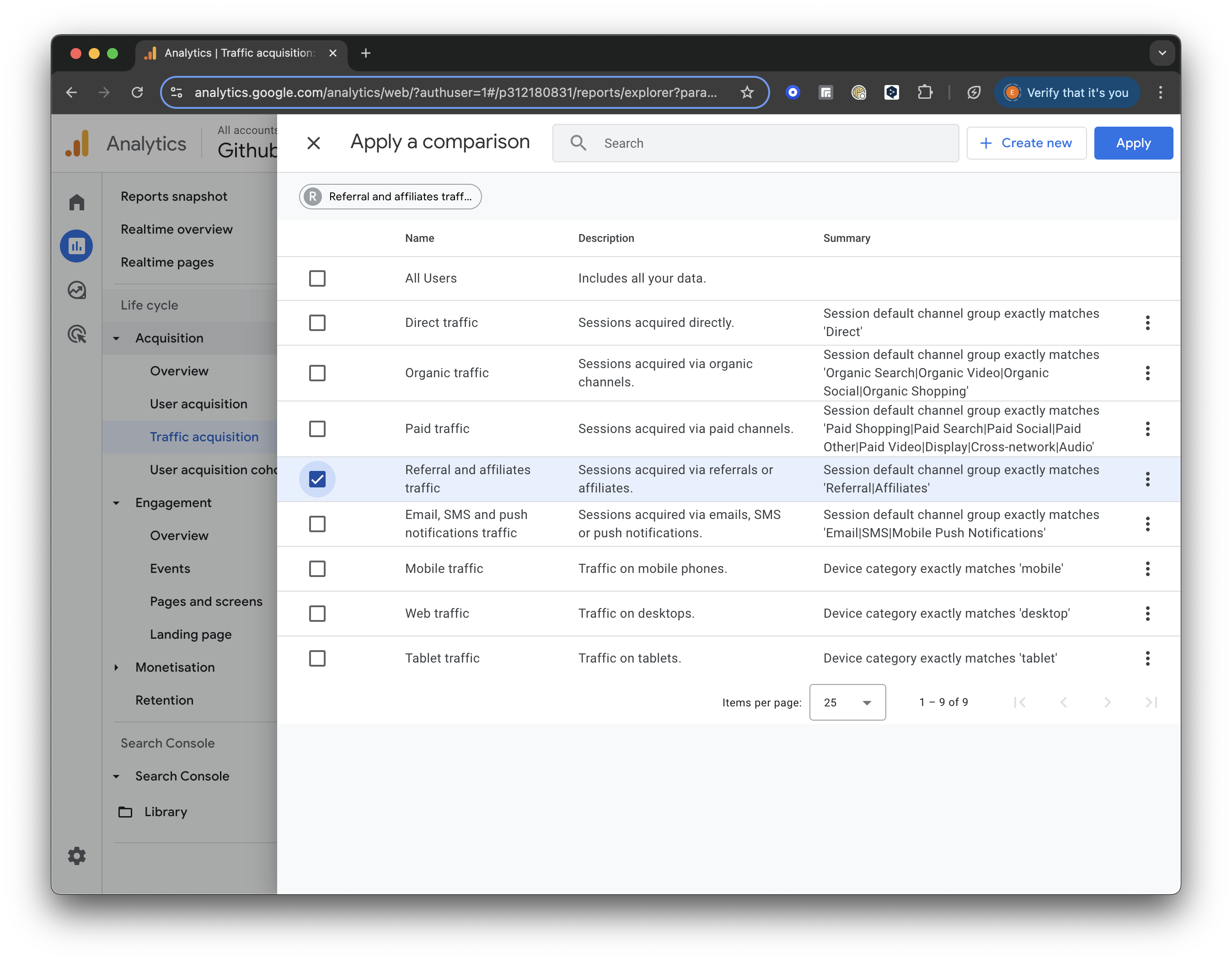
GA4 screenshot: Select Referral Traffic
Once selected, click “Apply” to save and view the updated report.
For all referral traffic, you will receive a detailed breakdown of sessions and engagement metrics (such as engaged sessions, engagement rate, and average engagement time).
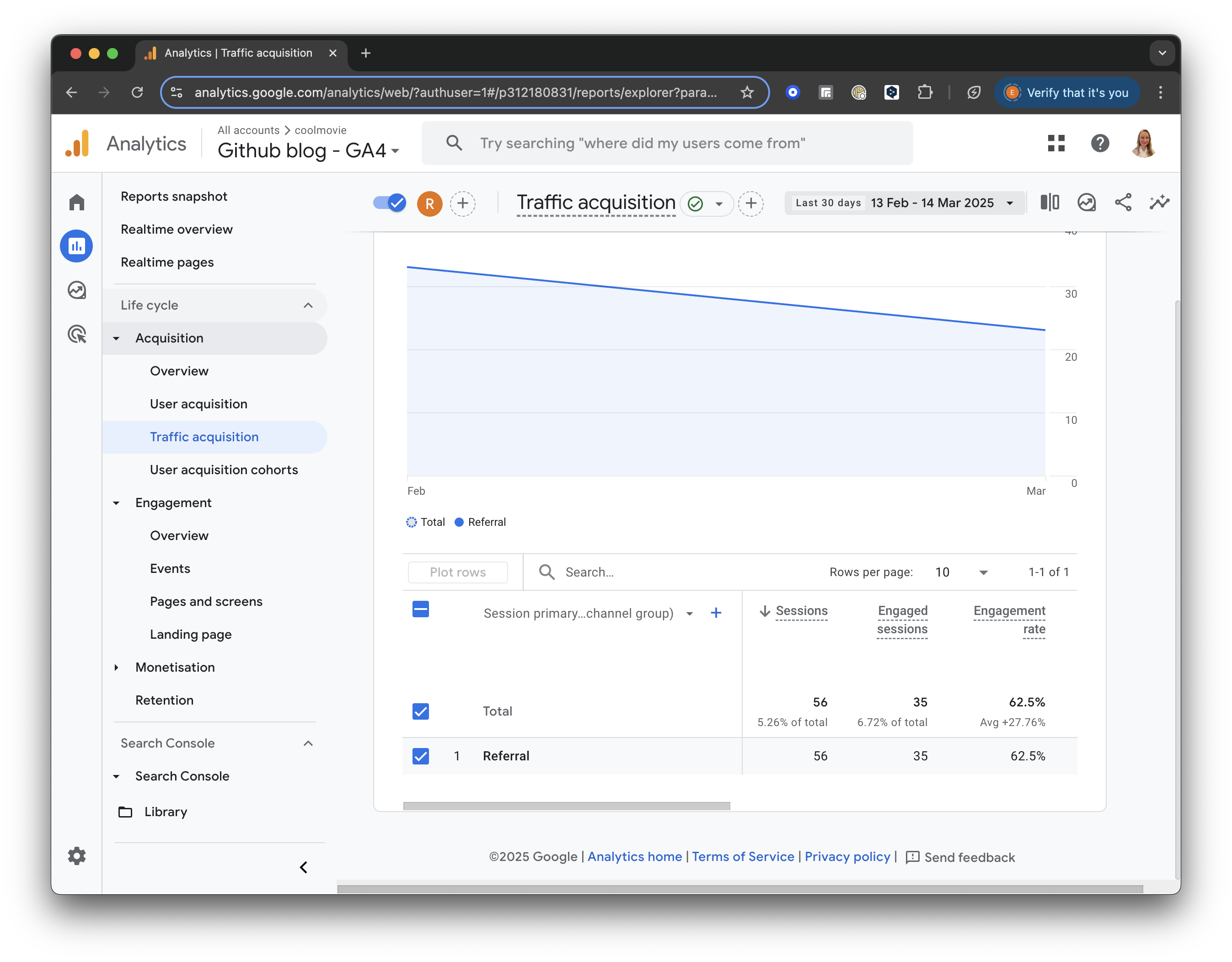
GA4 screenshot: Referral Traffic
Add a Secondary Dimension
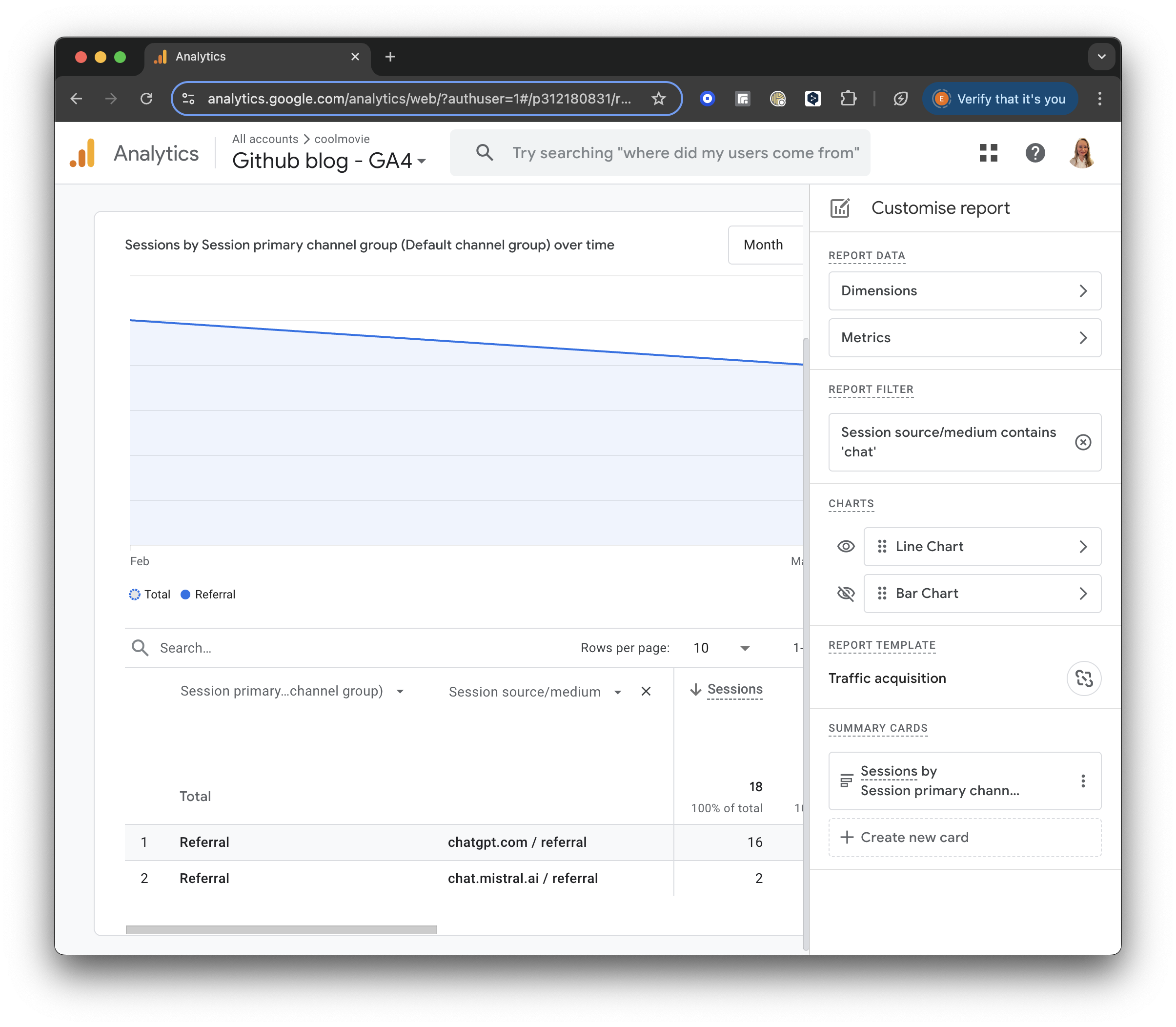
Next, let’s add a secondary dimension to analyse our traffic sources better.
Click the “+” icon next to “Session primary channel group” at the top of the table. Then, select Session Source/Medium from the list to add it as a secondary dimension.
GA4 screenshot: Session Source Medium
Build a filter
On the right side of the report, you will see a little pencil to “Customise the report.”
GA4 screenshot: Customise the Report
Press “+Add filter.” Then, find the Traffic Source section. Choose “Session source/medium” and set the Match Type to “contains.”
In the Value field, enter “chat” or another relevant keyword to filter for sessions from ChatGPT or similar sources.
GA4 screenshot: Chat Filter
Further, you can see which pages were visited by AI. In the table header, add “Page and screen class”, select “Page / Screen”, and then “Page path and screen class”.
In a result, you will see the pages visited by AI in the selected period:
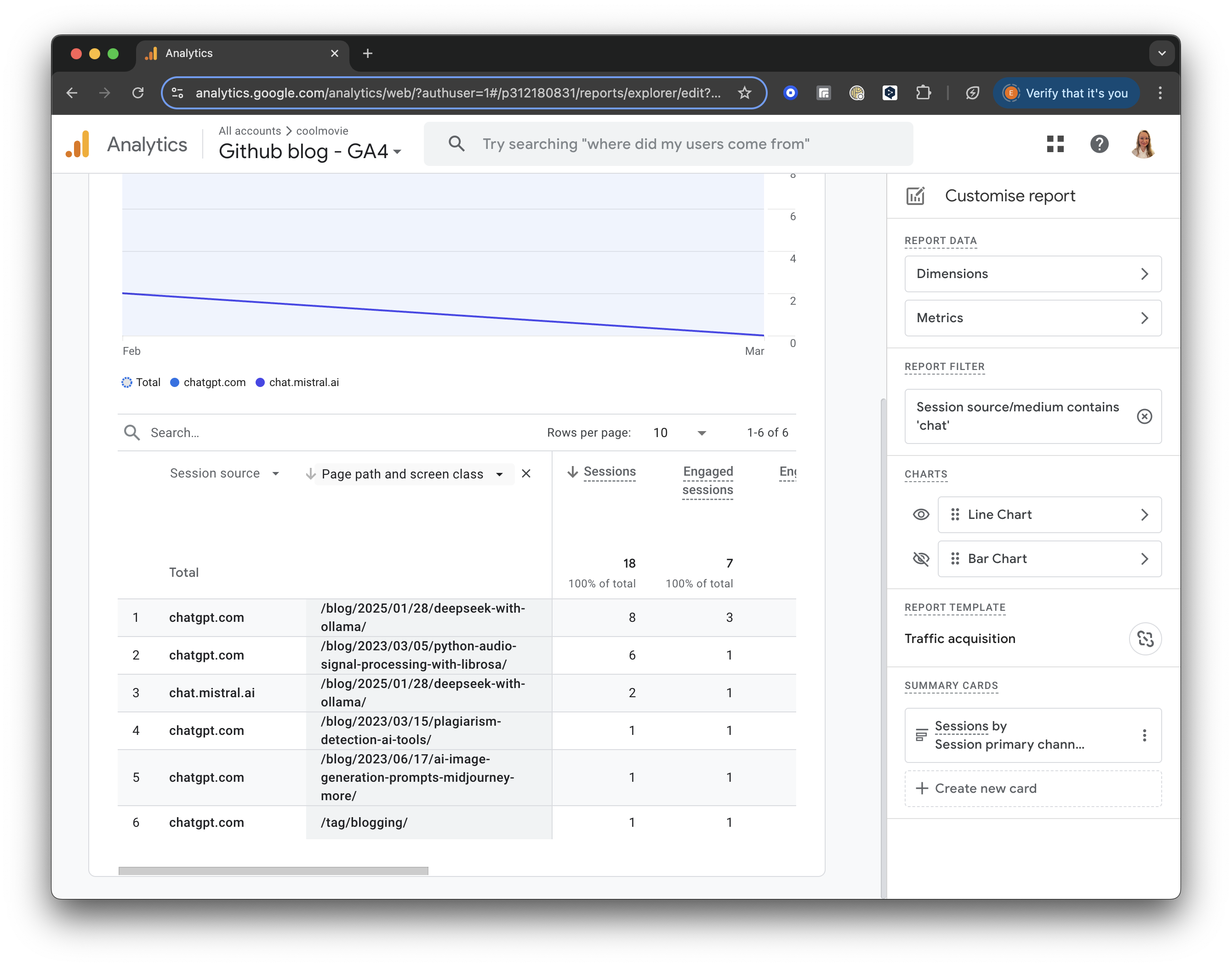
GA4 screenshot: AI Visited Pages
Implications
Is it good or bad that AI bots read my blog? There are several important implications to consider.
Firstly, I am happy that my content has become part of the data that AI systems may analyse, and my content could be further included in training datasets for various AI models. The ideas and knowledge I share influence AI responses. I also share my unique writing style with AI models learning from me :)
With AI bots such as chatGPT, I can reach a wider audience and indirectly generate more traffic without overly relying on search engines such as Google (which generates more than 90% of traffic for the majority of websites!).
The downside is that my authorship might not be properly attributed, and copyright protections exist but are still evolving in this space. I will also be unable to opt out of the LLM dataset once the content is public.
Crafting robots.txt
robots.txt is a text file webmasters create to instruct web robots (typically search engine robots) how to crawl pages on their website. It’s part of the robots exclusion protocol (REP), a group of web standards that regulate how robots crawl the web, access and index content, and serve it up to users.
It’s primarily used to prevent search engine crawlers from accessing certain parts of a website. This can be useful for avoiding indexing of duplicate content, keeping private areas of a website (like admin pages) out of search results, and reducing server load by preventing crawlers from accessing unimportant files.
robots.txt must be located in the root directory of a website (e.g., www.example.com/robots.txt).
robots.txt uses a simple text format with directives like:
* User-agent: Specifies which bot the rules apply to (e.g., Googlebot, * for all bots).
* Disallow: Specifies the paths the bot should not access.
* Allow: Specifies the paths the bot can access.
* Sitemap: Specifies the location of the XML sitemap.
robots.txt defines a set of guidelines, not a strict enforcement mechanism. Malicious bots can ignore it. It doesn’t guarantee that a page won’t be indexed if it’s linked to from other websites.
It’s crucial to use robots.txt correctly, as mistakes can accidentally block search engines from indexing important parts of your website.
How do I write robots.txt to let AI agents such as chatGPT index or exclude my content? Will it work?
You can use robots.txt to provide instructions to AI agents, including those that power chatbots like ChatGPT, regarding which parts of your website they can access and index. However, it’s crucial to understand the limitations and nuances of how different AI agents interpret and respect robots.txt directives.
It is not a system that prevents data from being used in AI training datasets.
Here’s a breakdown of how to write robots.txt for AI agents, along with considerations:
Basic robots.txt Syntax
User-agent:: Specifies the crawler or bot the rules apply to. You can use*to apply rules to all bots or specify a particular bot’s name.Disallow:: Specifies a URL path the specified bot should not access.Allow:: Specifies a URL path the specified bot can access. (Not all bots fully support this.)Crawl-delay:: Specifies the number of seconds a bot should wait between requests. (Not all bots respect this.)Sitemap:: Specifies the location of your XML sitemap.
You can find examples in How to write and submit a robots.txt file. In short, you can define which content is allowed and which should not be crawled by defined or all (use wildcard *) user agents:
-
Blocking all bots from your entire site:
User-agent: * Disallow: / -
Blocking a specific directory:
User-agent: * Disallow: /private/ -
Allowing access to a specific directory while blocking others:
User-agent: * Disallow: / Allow: /public/ -
Targeting specific AI agents:
- Many AI agents, including those used by OpenAI, will often respect the general ‘*’ rules. However, you can attempt to target them specifically.
- It is difficult to target all AI agents because they are constantly changing, and new ones arrive.
- Some agents may have specific user-agents.
- For example, trying and targeting OpenAI’s user-agent is possible. However, it is not guaranteed that this will always work.
User-agent: ChatGPT-User Disallow: /private/
Important Considerations
- Respect, Not Enforcement:
robots.txtis a set of guidelines, not a strict enforcement mechanism. Well-behaved bots will generally respect these rules, but malicious bots or those that ignorerobots.txtentirely can still access your site. - AI Agent Variability: AI agents may interpret
robots.txtdirectives differently. Some might be more compliant than others, and some may completely ignore the robots.txt file. - Caching: Some AI agents might cache content, so previously crawled content might still be used even if you update your
robots.txt. - Limitations:
robots.txtcannot prevent content from being indexed if linked to other websites. - No Guarantee: Even if a bot respects the
robots.txtfile, there is no guarantee that its content will be included in a large language model’s training data. - Training Data vs. Web Crawling: There is a difference between robots.txt, which tells web crawlers where they can and cannot go, and the datasets used to train large language models. Datasets for LLMs can be obtained from many sources, and are not limited to web crawling. Therefore, a robots.txt file will not prevent all use of your data, by all AI models.
- Future Changes: The landscape of AI and web crawling is constantly evolving. It is essential to stay updated on best practices, and the actions of the different AI models.
In summary, robots.txt is a helpful tool for providing guidelines to web crawlers, including some AI agents. However, it’s not a foolproof method for preventing all access or indexing. Be aware of the limitations and variability of AI agent behavior. Keep in mind that training data sets are not only built by web crawlers.
Conclusion
Tracking ChatGPT traffic with Google Analytics 4 is a valuable tool for understanding how AI chatbots visit your website and which pages might be valuable for their users. As we have seen lately, search engine traffic might be challenged in the future by generative AI search, and we must adapt to these changes while using web analytics tools such as GA4 to track AI bots and optimise our content for the new reality.
