
Introduction
What is machine learning? How is it implemented? There are so many concepts and steps to learn about machine learning. In this post, we will focus on briefly describing the machine learning process.
We start with the machine learning definition. There are so many definitions of machine learning. This field is part of artificial intelligence and builds on top of statistics, probability, computer science and even neurobiology (when we are creating artificial neural networks).
If you have not read it yet, I advise you to read a fundamental must-read by Mitchell, T. M. (1997) “Machine Learning”. McGraw-Hill”. This book covers the core algorithms such as decision trees (one of my favourites :), Bayesian learning, reinforcement learning, and K-nearest neighbour learning, among other things we should be aware of.
In his book, Machine Learning, Mitchell defines the machine learning as:
The field of machine learning is concerned with the question of how to construct computer programs that automatically improve with experience.
To simplify, we create programs that take in data and produce desired results in machine learning. There are several stages in the machine-learning process that we briefly describe next.
Machine-learning process
The machine learning process involves steps and activities designed to develop and deploy machine learning models to solve specific problems or make predictions.
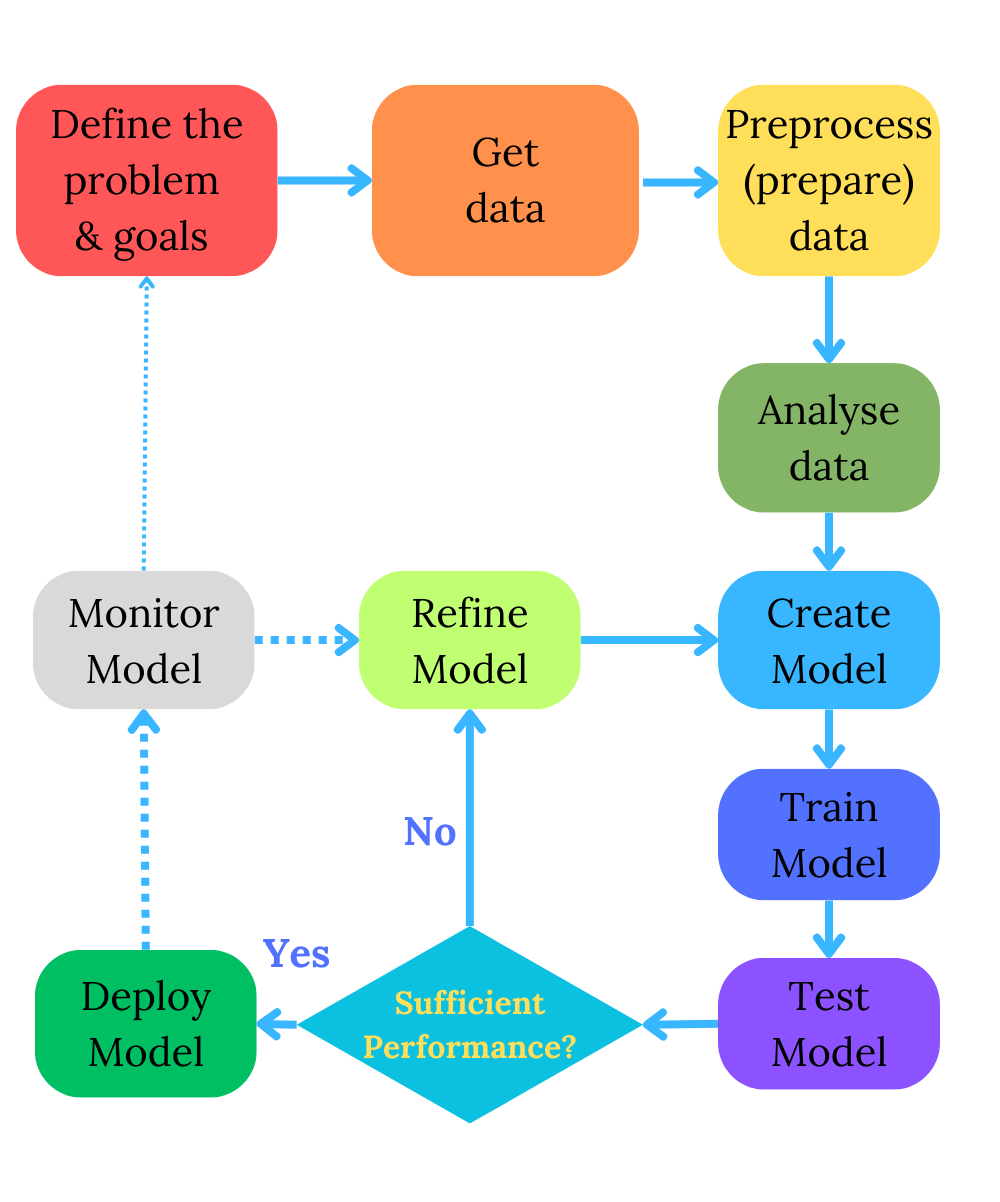
One picture is worth a thousand words. You see the simplified diagram of a machine-learning process, which is more intricate in practice.
The primary objective of supervised learning
The primary objective of any supervised machine learning algorithm is to accurately determine the mapping function that links the input data (X) to the output variable (y). In simpler terms, this mapping function is akin to a hidden pattern or relationship within the data that the algorithm aims to uncover and comprehend.
In simple terms:
-
Supervised machine learning is a category of algorithms where the model is trained on a labeled dataset, with known input-output pairs. The ultimate goal is to develop a model that can predict or estimate the output variable (y) for new, unseen input data (X) accurately.
-
The “mapping function” refers to the mathematical or statistical relationship that the algorithm seeks to establish between the input data and the target output. It essentially defines how changes in the input data correspond to changes in the output variable.
-
The mapping function can be thought of as a concealed pattern or structure within the data. The algorithm’s job is to uncover this hidden pattern and utilize it to make predictions. This pattern might not be immediately obvious and may require complex mathematical modeling to reveal.
In essence, supervised machine learning endeavors to discover the underlying patterns within the data that enable accurate predictions. This process involves finding and quantifying the relationship between input features and the target output, allowing the algorithm to generalize from the training data to make predictions on new, unseen data.
Further, we overview the machine-learning steps which are suitable to follow for creating well-performing models.
Problem Definition
As in any complex process, we start by defining the problem you want to solve or the question you want to answer using machine learning. This step includes identifying the objectives and goals, understanding the problem’s context, and determining the project’s scope.
Data Collection
The next step is gathering the data to train and test machine learning models. Data can come from various sources, such as databases, APIs, sensor data, or external datasets. Data quality and relevance are crucial at this stage.
Data Preprocessing
We will also have to prepare data or “preprocess” it, clean and brush it over so that the data can be useful for our algorithms. Some algorithms, such as regression, work the best with numeric data, while others, such as decision trees, can take in well categorical values.
Before using the data for training machine-learning models, it often requires cleaning, transformation, and preprocessing. This includes handling missing values, encoding categorical features, scaling, and normalization.
On this blog, you can read more about data exploration and wrangling in the post Data Exploration and Analysis with Python Pandas.
Data Splitting
We want our trained model to perform well. When well trained, the model might achieve a very high accuracy using the “training dataset”. However, we want to achieve an excellent model performance on unseen data or data unknown to the model. This data is called the “test dataset” for evaluating the model’s performance. We will need to have also a validation set for hyperparameter tuning. This separation helps assess the model’s ability to generalize to unseen data.
Feature Engineering
Feature engineering involves selecting, creating, or transforming features (input variables) to improve the model’s performance. Practical feature engineering can enhance a model’s ability to find patterns and make accurate predictions.
Model Selection
We must choose the appropriate machine learning algorithm or model for the problem. Selection depends on factors like the nature of the problem (classification, regression, clustering), the dataset’s size, and the desired output.
With sufficient experience and some guidelines, we can find the algorithms that should work well for particular cases. Some algorithms require human involvement for labelling data samples. For instance, we employ supervised machine learning when doing image classification. We provide a label for each image in the training dataset. In other algorithms, we do not give any labels. These algorithms are called “unsupervised learning” and work as a “magic box” without much human involvement.
You can read more about the machine-learning approaches, including supervised learning, unsupervised and reinforcement learning and algorithms at Machine learning.
Model Training
Next, we use the training dataset to train the selected model. The model learns from the data by adjusting its parameters to minimize prediction errors. This process involves optimization techniques like gradient descent.
Hyperparameter Tuning
Each algorithm or machine-learning technique has a set of parameters that we can adjust while creating a model. We fine-tune the model by adjusting its hyperparameters. This is typically done using the validation dataset. Techniques like grid search and random search can help find the best hyperparameters.
Model Evaluation
Assess the model’s performance using the test dataset. Standard evaluation metrics vary based on the problem type. For example, accuracy, precision, recall, F1 score, or mean squared error are used depending on the context.
In one of my previous posts Machine Learning Tests using the Titanic Dataset, we go through the whole machine learning experimentation process, starting from the data preprocessing, including feature engineering and selection, and finishing by comparing several supervised models.
Model Deployment
If the model performs well, it can be deployed to make predictions in a real-world environment. Deployment can involve integrating web applications, mobile apps, or other systems.
Monitoring and Maintenance
Once deployed, the model needs continuous monitoring to perform as expected. Over time, data distributions can change, leading to model drift. Regular updates and maintenance are essential.
Documentation and Communication
We document the entire process, including the problem statement, data sources, preprocessing steps, model architecture, and results. Effective communication of results is crucial for stakeholders.
Reiteration and Improvement
As the image shows, we rarely stop refining the model after the deployment step. We might redefine the goals, collect data and re-create the model again after monitoring the model in a real-life setting.
The machine learning process is often iterative. If the model’s performance is unsatisfactory, you may need to revisit previous steps, improve data quality, or experiment with different models.
Conclusion
In short, machine learning is like teaching computers to learn from examples instead of programming them explicitly—the machine-learning process can vary in practice depending on the specific problem, data, and goals.
The following posts will focus on the essential concepts and techniques for building and evaluating models in machine-learning experiments. Come again soon!
Did you like this post? Please let me know if you have any comments or suggestions.
Posts about Machine Learning that might be interesting for youReferences
1. Mitchell, T. M. (1997). Machine Learning. McGraw-Hill
2. Data Exploration and Analysis with Python Pandas
