
Introduction
Humans experience the world through multiple senses: sight, hearing, touch, smell, and taste. We combine information from these senses to understand our surroundings. Multimodal AI aims to give computers similar abilities, allowing them to process and understand information from multiple modalities (senses) like text, images, audio, and video.
What is Multi-modality in AI?
Multi-modality in AI means that an artificial intelligence system can process and combine information from different types of inputs. Instead of using just text, images, or audio, a multimodal AI can understand how these different forms of data relate to each other.
These examples illustrate how multimodal AI can integrate and interpret information from different modalities to enhance understanding and interaction in various application domains:
-
Image Captioning: When you upload a photo of a sunset, multimodal AI can analyze the image and generate a descriptive caption, like “A beautiful sunset over the ocean with vibrant orange and purple hues.”
-
Video Analysis: In the case of a sports video, multimodal AI can identify the players (visual), understand the rules of the game (context), and provide real-time commentary or analysis based on what’s happening (audio and textual data).
-
Chatbots with Visual Recognition: A chatbot can process an uploaded image of a product and provide information about it. For example, if you send a picture of a smartphone, the AI can recognize the model and provide details like specifications, pricing, and reviews.
-
Interactive Learning: In educational apps, when a student draws a diagram of the solar system, multimodal AI can recognize the shapes (visual) and then provide information about each planet’s characteristics (audio/text).
-
Speech-to-Text with Context Understanding: When you speak about a specific location while looking at a map on your device, multimodal AI can transcribe your speech (audio) and highlight the location on the map (visual) for better comprehension.
-
Augmented Reality (AR) Apps: An AR application can overlay digital information onto a physical object. For instance, pointing your phone at a landmark can trigger visual overlays, such as historical facts or 3D models, while providing audio guides about the site.
-
Medical Imaging Analysis: Multimodal AI can combine data from various medical imaging techniques like CT scans, MRIs, and PET scans to detect cancer. For instance, by analyzing a CT scan of a patient’s abdomen, the AI can identify suspicious masses (visual data) and correlate this information with patient history and genetic data (textual data) to assess the likelihood of cancer. Additionally, it might integrate radiology reports (textual) and lab results (numerical) to provide a comprehensive diagnosis, enhancing the accuracy of cancer detection and characterization.
How is Multi-modality Realised?
Core techniques
Several techniques and architectures enable multimodal AI:
- Early Fusion: This approach combines data from different modalities early before significant processing occurs. For example, image features and text embeddings might be concatenated (joined together) and fed into a neural network.
- Late Fusion: In this method, each modality is processed separately, and the results are combined later, usually through a fusion layer or a decision-making process. This allows each modality to be processed with specialised models.
- Joint Representations: This aims to learn a shared representation space where data from different modalities can be compared and related. This is often achieved using techniques like contrastive learning, where the model learns to distinguish between matching and non-matching data pairs from different modalities.
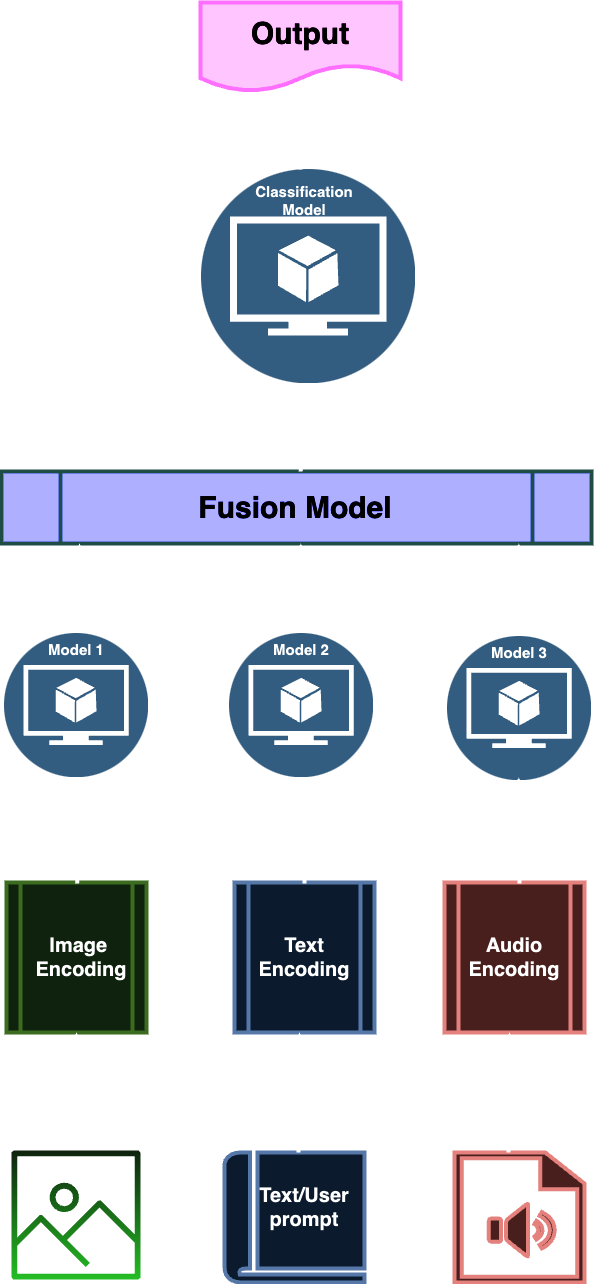
Here, we see how the late fusion multi-modality is realised in three general steps:
- The input modalities are encoded and their features extracted;
- The extracted features are combined in the fusion model;
- The fused data can be used by the classifier or other model to make the prediction.
Research
Next, the following review and research papers can be a starting point to further understand multimodal AI in detail:
-
The review by Zhang with coauthors in Multimodal Intelligence: Representation Learning, Information Fusion, and Applications analyses recent works on multimodal deep learning from three perspectives: representation learning, a fusion of signals, and applications. It highlights key concepts of embeddings that unify multimodal signals into a single vector space, enabling cross-modality processing and various downstream tasks. The review also examines architectures for integrating unimodal representations for specific tasks. Additionally, it covers applications like image-to-text caption generation, text-to-image generation, and visual question answering. This review aims to support future studies in the field of multimodal intelligence.
-
The multi-modality AI fusion-related research paper by Gadzicki with coauthors Early vs Late Fusion in Multimodal Convolutional Neural Networks investigated the impact of fusing information from various data sources on human activity recognition using convolutional neural networks. The findings indicate that any form of fusion enhances performance, regardless of timing or modality. Notably, early fusion outperforms late combination, achieving 86.7% compared to 82.3% and 82.9%. This supports the idea that a multimodal convolutional network can effectively leverage the multivariate correlations among data sources.
-
The research paper by Nakada with coauthors Understanding Multimodal Contrastive Learning and Incorporating Unpaired Data paper explored a class of nonlinear loss functions for multimodal contrastive learning (MMCL) and its connection to singular value decomposition (SVD). Authors demonstrate that gradient descent in loss minimisation is akin to performing singular value decomposition on a cross-covariance matrix. Their analysis shows that MMCL can outperform unimodal contrastive learning, even with incorrect matches, highlighting its robustness to noisy data.
-
Vision-Language Pre-training (VLP) (the most advanced techniques are surveyed in Vision-Language Pre-training: Basics, Recent Advances, and Future Trends) is one of the most advanced models in Contrastive Language–Image Pre-training (CLIP) by OpenAI (CLIP: Connecting text and images). CLIP learns to associate images and text descriptions by training on a massive dataset of image-text pairs. It excels at zero-shot image classification and cross-modal retrieval.
-
Multimodal Transformers are where Transformers, initially designed for natural language processing, have been adapted for multimodal tasks. Models like ViLBERT (Vision-and-Language BERT) (https://arxiv.org/abs/1908.02265) and LXMERT (Learning Cross-Modality Encoder Representations from Transformers) (https://arxiv.org/abs/1908.07490) use transformer architectures to jointly process visual and textual information. These models have shown strong performance on tasks like visual question answering (VQA) and image-text retrieval.
-
Text-to-Image Generation is realised in models like DALL-E 2 (https://openai.com/dall-e-2/) and Imagen (https://imagen.research.google/) have revolutionized text-to-image generation. These models use sophisticated techniques, including diffusion models and transformer architectures, to generate highly realistic and creative images from textual descriptions. They demonstrate a deep understanding of the relationship between language and visual concepts. Stable Diffusion (https://stability.ai/blog/stable-diffusion-public-release) is an open-source alternative that has democratised access to this technology.
-
Video Understanding requires processing both visual and auditory information over time. Models like VideoBERT (https://arxiv.org/abs/1904.02811) extend the BERT architecture to video by incorporating visual features. More recent work focuses on incorporating temporal information and using transformer-based architectures for tasks like video captioning, action recognition, and question-answering.
-
Multimodal Conversational AI, which combines text, voice, and visual cues, is crucial for building more natural and engaging conversational AI systems. Research in this area explores integrating these modalities to improve dialogue understanding, context awareness, and user experience.
What are the most popular multimodal AI?
Please notice we don’t aim to do any ranking of multimodal AI, we can just name several widely recognised multimodal AI models:
-
Sora by OpenAI is a text-to-video model that generates videos from textual descriptions. Sora takes text prompts as input and generates video as output. This interaction between two distinct modalities (text and visual) is a key characteristic of multimodal AI. Cora “understands” relationships between modalities: To generate coherent videos from text, Sora needs to understand the semantic relationships between words and visual concepts. It needs to know how objects move, how scenes are composed, and how actions unfold over time. This understanding of cross-modal relationships is a hallmark of multimodal AI. The technology review by Liu and coauthors examines Sora covers Sora’s background, technologies, applications, challenges, and future directions, highlighting its impact on sectors like filmmaking, education, and marketing.
-
CLIP (Contrastive Language–Image Pre-training) by OpenAI works with text and images and is excellent at zero-shot image classification and cross-modal retrieval (finding images based on text descriptions and vice versa). It has become a foundation for many other multimodal models. CLIP is widely used in various applications, including image search and content moderation, and as a component in more complex systems.
-
DALL-E 2 & 3 by OpenAI works with text and images to generate highly realistic and creative images from text descriptions. It demonstrates a strong understanding of language and visual concepts. DALL-E 3 has improved prompt following and image quality significantly.
-
Imagen by Google is a powerful text-to-image model known for its high-quality image generation and deep understanding of textual prompts. Imagen contributed to advancements in text-to-image technology and pushed the boundaries of image realism and coherence.
-
Stable Diffusion by Stability AI is a well-known open-source text-to-image model that has democratised access to this technology. It is highly adaptable and has a large community contributing to its development. Stable Diffusion Made text-to-image generation accessible to a wider audience, leading to a surge in creative applications and community-driven innovation.
-
ImageBind by Meta AI integrates six modalities: Images, Text, Audio, Depth, Thermal, and IMU data. IMU data, collected by Inertial Measurement Units using accelerometers and gyroscopes, measures specific force and angular rate. It is essential for navigation in vehicles, smartphones, and drones, ensuring accurate motion and position tracking - read more at IMU. ImageBind combines information from various modalities, enabling more comprehensive understanding and cross-modal tasks.
-
LaVA (Large Language and Vision Assistant) combines a large language model with a vision encoder for visual question answering and image-based dialogue. Check their GitHub repository at NeurIPS’23 Oral Visual Instruction Tuning (LLaVA) built towards GPT-4V level capabilities and beyond.
-
ViLBERT and LXMERT:** Early and influential models that use Transformers to jointly process visual and textual information. You can learn about these models in papers by Lu with coauthors at ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks and LXMERT: Learning Cross-Modality Encoder Representations from Transformers by Tan and Bansal.
It’s important to note that this field constantly evolves, with new models and techniques emerging regularly. These examples represent some of the most prominent and impactful multimodal AIs that have significantly advanced the field.
The Future of Multimodal AI
Multimodal AI is a rapidly evolving field with immense potential. By combining information from multiple sources, AI systems can gain a more comprehensive understanding of the world, leading to more accurate and robust applications in various domains, including healthcare, education, and robotics. For instance, a multimodal AI could analyse patient data from medical images, electronic health records, and doctor-patient conversations to provide more accurate diagnoses and personalised treatment plans.
The future of multimodal AI is incredibly promising. We can expect to see:
Advanced models development that can easily connect information from different sources (like touch and smell). Better reasoning and understanding features that help AI systems handle more complicated tasks needing cross-source thinking. Greater use of multimodal AI in many fields, such as robotics, healthcare, education, and entertainment.
By exploring multimodal research further, we can help AI understand and interact with the world more like humans do.
Conclusion
Multimodal AI is revolutionising how machines perceive and interact with the world by integrating information from diverse sources like text, images, and audio. Models like CLIP, DALL-E, and Stable Diffusion demonstrate the immense potential of this field, paving the way for more intelligent and human-like AI systems.
Did you like this post? Please let me know if you have any comments or suggestions.
Posts about AI that might be interesting for youReferences
1. Multimodal Intelligence: Representation Learning, Information Fusion, and Applications
2. Early vs Late Fusion in Multimodal Convolutional Neural Networks
3. Understanding Multimodal Contrastive Learning and Incorporating Unpaired Data
4. Vision-Language Pre-training: Basics, Recent Advances, and Future Trends
5. Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
6. CLIP: Connecting text and images
7. https://arxiv.org/abs/1908.02265
8. https://arxiv.org/abs/1908.07490
9. https://openai.com/dall-e-2/
10. https://imagen.research.google/
11. https://stability.ai/blog/stable-diffusion-public-release
12. https://arxiv.org/abs/1904.02811
13. https://openai.com/research/clip/
14. https://openai.com/dall-e-2/
15. https://imagen.research.google/
16. https://stability.ai/blog/stable-diffusion-public-release
18. Visual Instruction Tuning (LLaVA) built towards GPT-4V level capabilities and beyond.
19. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
20. LXMERT: Learning Cross-Modality Encoder Representations from Transformers
