
Introduction to AI Music Generation
Artificial intelligence (AI) has reshaped many industries, and music is no exception. AI music tools are software applications that use machine-learning algorithms to create, modify, and produce music. These tools transform the music industry by enabling musicians, producers, and composers to create high-quality music with minimal effort and time. Besides, anyone can create wonderful audio pieces automatically in no time!
In this post, we will get into music generation with AI. We will briefly explore existing AI applications generating audio. We will analyse transformer usage while coding music generation with HuggingFace transformers in Python. We will also get informed about a few AI tools that can produce audio files without coding.
What Is AI-Generated Music?
Generating music with AI involves collecting a dataset of existing music, preprocessing it into a format the AI model can understand, and then training the model using various algorithms, such as recurrent neural networks (RNNs) or transformers or generative adversarial networks (GANs). The trained model can generate music by taking a starting point (a seed) and predicting subsequent musical elements.
Researchers and musicians can guide the AI’s output by adjusting parameters like style, tempo, or complexity. While AI-generated music can be impressive and innovative, it’s important to note that it needs more true creativity and emotions, often relying on learned patterns rather than genuine inspiration. Nonetheless, AI-generated music can be valuable for composers, artists, and enthusiasts exploring new musical ideas or overcoming creative blocks.
In my final year at musical school, I orchestrated a comedy of errors. While fine-tuning for exams, I moonlighted at a computer club, whipping up Basic programs. Imagine my grand entrance – late, lugging piano books (just for show). "Sorry, got lost in a symphony," I'd chime.
Facing the music – or, in this case, a computer science teacher's stern gaze – I got a harsh ultimatum: "Keys on a keyboard or keys on a piano?" Refusing to choose, I did the logical thing: pledged allegiance to both.
Victory danced my way. The teacher's severe façade cracked; I suspect secret dreams of moonlighting as a disco DJ.
Lesson learned: When life throws keys and code at you, compose a hilarious masterpiece.
AI Music Generation Apps and Tools
First, let’s see what AI tools can be used without or with minimal coding. These tools enable individuals such as content creators, musicians, advertisers, event organisers, fitness instructors, and more to craft a wide range of music styles, from basic beats to intricate orchestrations, addressing their unique needs.
There are quite a few AI apps that can generate music:
- orbplugins.com is a set of AI plugins for professional and creative music creation. The features of Orb Synth X are shown in the YouTube, Orb plugins.
- Boomy.com AI tool that can create fantastic tunes within seconds, regardless of your musical background; share your tracks on streaming services with a supportive worldwide community of generative music creators.
- evokemusic.ai is another AI tool to generate good quality music, evokemusic.ai offers a collection of audio files.
- ecrettmusic.com sia great music creation tool for content creators. Their royalty-free music can be used to add music tracks to games, YouTube videos, and social media podcasts. You can’t make your generated music downloadable and shared plainly.
- With mubert, you can instantly produce custom tracks that flawlessly complement your content across various platforms, such as YouTube, TikTok, podcasts, and videos.
- Soundful, another notable choice, appears to excel in generating precise outputs compared to Mubert, though some non-electronic results were underwhelming.
- Aiva (Artificial Intelligence Virtual Artist) enables users to customise and create original music by adjusting parameters like mood, style, and instrumentation.
- beatoven.ai creates distinctive mood-matched music tailored to complement every segment of your video or podcast.
- beatbot.fm produces concise songs from your text inputs.
- Magenta Studio is a set opensource tools and models harnessing advanced machine learning methods for music creation, accessible as standalone apps or Ableton Live plugins; explore further via the provided links. Check out their Demos that also showcase coding examples.
- riffusion uses GPT technology to generate music from text prompts.
- OpenAI’s Jukebox library is another fantastic choice for coders exploring the music generation process with the newest AI technology.
By the way, I like country music made with Jukebox :)
It is so exciting! You can also generate a remarkably natural and expressive singing voice with the VOCALOID. I have not tried it yet since I am into the process rather than the result :)
We might try out all of these beautiful tools. However, we like coding and will go into creating music in Python immediately. We will explore HuggingFace pre-trained models for audio generation. Let’s go!
Transformers for music generation
Transformers are basically artificial neural networks; which can be used to generate text, images, and music fragments. Designing and developing such networks takes time and data to train and test the developed machine learning models. A general approach to applying Machine Learning for music generation:
-
Convert your musical data (notes, chords, etc.) into a format that an ML model can tokenise. This typically involves representing each musical element as a token.
-
Create or choose a suitable pre-trained model, for instance, using HuggingFace transformers.
-
Fine-tuning a pre-trained model specifically for music generation might be more complex than with text. However, you can experiment by training on a music-related dataset and adjusting the model’s loss function to encourage musical coherence and creativity.
-
Once you have a trained model, you can use it to generate music. Provide a starting seed (a few initial tokens) and then iteratively generate subsequent tokens based on the model’s predictions. It would help if you experimented with techniques like temperature and nucleus sampling to control the randomness of the generated music.
-
Convert the generated token sequences to a musical format you can listen to or analyse. This could involve mapping tokens to notes, chords, or other musical elements.
HuggingFace Transformers is a popular library for working with various natural language processing (NLP) models. While the library primarily focuses on NLP tasks, it can also be used for creative tasks like music generation by treating musical sequences as sequences of tokens, similar to text.
Their MusicGen transformer — a model that generates audio from text descriptions or melody inputs — can be used to generate audio files, and if you have no patience to code and read this post to the end, check their demo webpage :)
Generating Music with HuggingFace Transformers and MusicGen
Now, let’s generate music with the help of HuggingFace’s MusicGen using a few lines of Python code.
We can use Google Colab to execute the code on GPU. You are free to use your own setup that allows sufficient computational resources.
Let’s go through the steps of using HuggingFace’s MusicGen to generate music while learning how to use the MusicGen transformer:
The preparation steps are:
- Run in GPU (in Runtime menu, and run !nvidia-smi) if available;
- Installation and import of the transformers
Next, we will go through a few examples of using pre-trained models in HuggingFace:
- Load an existing model (MusicGen) from HuggingFace’s transformers;
- Choose hardware;
- Define generation mode;
- Get inputs for null generation (unconditional);
- Play or save the generated sample;
- Use text prompts (play with different prompts, guidance scale);
- Use audio inputs;
- Try batched audio generation with text prompts;
The HuggingFace transformers code is the GitHub repository
The MusicGen in Transformers is explained in the notebook by Sanchit Gandhi, a researcher at HuggingFace. I recommend reading his papers.
We will follow the code in the notebooks and get more in details. You will find more notebooks related to the audio processing notebooks in the repository folder.
Preparation: Installing Transformers and Audio Libraries
In Google Colab, we want to select the GPU runtime environment, which can be done via the “Runtime” menu. Confirm that you are using GPU with:
!nvidia-smi
Thu Aug 24 10:29:16 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 51C P8 10W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
To install transformers and datasets, run in the Colab cell as follows MusicGen.ipynb:
!pip install --upgrade --quiet pip
!pip install --quiet git+https://github.com/huggingface/transformers.git datasets[audio]
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.1/2.1 MB 27.0 MB/s eta 0:00:00
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing metadata (pyproject.toml) ... done
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.8/7.8 MB 51.7 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 115.3/115.3 kB 14.6 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 268.8/268.8 kB 29.0 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.3/1.3 MB 80.0 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 519.3/519.3 kB 43.7 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 134.8/134.8 kB 17.9 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 194.1/194.1 kB 26.9 MB/s eta 0:00:00
Building wheel for transformers (pyproject.toml) ... done
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
We will use Colab’s “files” library for downloading generated audio files:
# We will use the files library for downloading audio files generated with AI
from google.colab import files
Using Pre-Trained MusicGen Models
Load an existing model
Let’s start with an audio generation that HuggingFace’s transformers can perform. MusicgenForConditionalGeneration has a pre-trained model that can generate audio. As we see from the name, MusicgenForConditionalGeneration is for conditional generation based on some given conditions or inputs.
Next, we can load a pre-trained model (“facebook/musicgen-small”) from the Hugging Face Transformers library:
from transformers import MusicgenForConditionalGeneration
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
Downloading (…)lve/main/config.json: 100% 7.87k/7.87k [00:00<00:00, 299kB/s] Downloading pytorch_model.bin: 100% 2.36G/2.36G [00:13<00:00, 284MB/s] Downloading (…)neration_config.json: 100% 224/224 [00:00<00:00, 16.1kB/s]
MusicGen is an auto-regressive Transformer model that creates high-quality music samples based on text descriptions or audio prompts. It employs a text encoder to generate hidden-state representations from text descriptions, which are then used to predict audio tokens. These tokens are decoded with an audio compression model like EnCodec to reconstruct the audio waveform. Read more about MusicGen
Please note that there are more pre-trained models, as explained in MusicGen: Simple and Controllable Music Generation:
facebook/musicgen-small: 300M model, text to music only
facebook/musicgen-medium: 1.5B model, text to music only
facebook/musicgen-melody: 1.5B model, text to music and text+melody to music
facebook/musicgen-large: 3.3B model, text to music only
However, larger-sized models will require more memory, and you will need to pay for additional computation power when using Google Colab. I recommend starting with the small model if you use the free Colab plan.
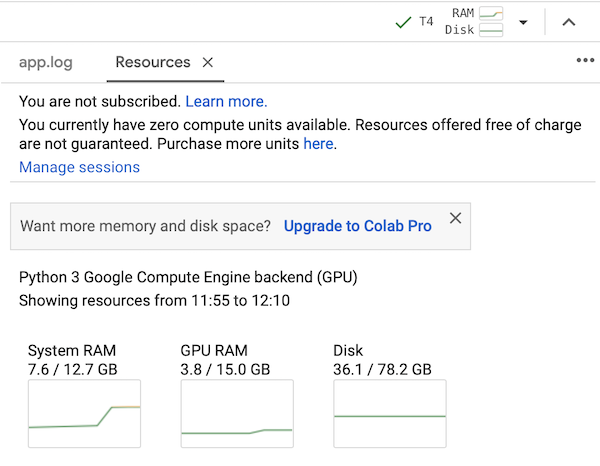
Colab, free plan using T4 tesla
Please notice that the RAM and disc usage indicators in the top right corner are quite useful. Sometimes, you have to free the cache memory:
# Empty the cache memory
import torch
torch.cuda.empty_cache()
What is GPU acceleration?
GPU acceleration refers to the use of Graphics Processing Units (GPUs) to perform computations in parallel, significantly speeding up certain types of tasks and calculations. While GPUs were initially developed for rendering graphics in video games and graphical applications, their highly parallel architecture makes them well-suited for a wide range of general-purpose computing tasks beyond graphics.
Traditional Central Processing Units (CPUs) focus on executing a few complex tasks sequentially. CPUs are optimised for jobs that require high single-threaded performance and versatility. On the other hand, GPUs consist of thousands of smaller, simpler cores designed for parallel processing. This design makes GPUs exceptionally efficient for tasks that can be broken down into many smaller sub-tasks that can be executed simultaneously.
GPU acceleration is particularly valuable for tasks that involve massive amounts of data processing, such as:
-
Deep Learning and Machine Learning: Training complex neural networks involves numerous matrix multiplications and other mathematical operations. GPUs excel at performing these operations in parallel, significantly speeding up the training process.
-
Scientific Computing: Fields like physics, chemistry, and biology often involve simulations and complex calculations that can benefit from the parallel processing power of GPUs.
-
Image and Video Processing: Tasks like image and video editing, rendering, and compression can be accelerated using GPUs, as these tasks often involve manipulating large amounts of data.
-
Cryptocurrency Mining: Mining cryptocurrencies requires performing vast numbers of calculations, making GPUs popular for this purpose.
-
Financial Modeling: Analysing and modelling financial data involving complex mathematical calculations can also benefit from GPU acceleration.
When GPU acceleration is used effectively, it can lead to significant speedup compared to running the same tasks on CPUs alone. However, not all jobs can take full advantage of GPU acceleration. It’s essential to determine whether a task’s nature and structure align with the parallel architecture of GPUs to make the most out of this technology.
I am affiliated with and recommend the following fantastic books for learning Python and mastering your audio processing and digital music programming skills.
Introduction to Digital Music with Python Programming. Learning Music with CodeIntroduction to Digital Music with Python Programming - offers beginners a foundation in music and coding, demonstrating how they can enhance creative expression and streamline production processes. Through interactive examples covering rhythm, chords, and melody, the book teaches core programming concepts without requiring prior experience in music or coding. |
|
|

|
The Python Audio Cookbook. Recipes for Audio Scripting with PythonThe Python Audio Cookbook is an important guide for those wanting to use Python in sound and multimedia projects. It explains audio synthesis techniques and GUI development in easy-to-understand terms, helping both beginners and experienced programmers create exciting audio projects. |
|
|

|
Choosing hardware
Ideally, we want a GPU acceleration. We can use the CPU if a GPU is not available.
# We want to use accelerator hardware when available otherwise - CPU
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model.to(device);
The function torch.cuda.is_available() (PyTorch library) checks whether a GPU (CUDA) is available for computation. If a GPU is available, it returns True. Otherwise, it returns False.
If a GPU is available, the value “cuda:0” is assigned to the variable device, indicating that the computation should be performed on the first GPU. If a GPU is unavailable, it gives the value “cpu” to the variable device, indicating that CPU will be used.
device
cuda:0
This approach allows your code to automatically select the appropriate device based on the availability of GPUs, ensuring efficient computation by utilising GPUs when they are available and falling back to CPU when necessary.
Define generation mode
There are two generation modes: greedy and sampling. When using sampling generation, we can get better results. For this, use do_sample=True (default value).
We can start to generate audio samples without any specific conditions or constraints. For this, the get_unconditional_inputs function of the model is called, generating a set of inputs for the model to generate audio. The parameter num_samples is set to 1, indicating that you want to create a single audio sample.
To obtain null generation (unconditional) inputs, run:
unconditional_inputs = model.get_unconditional_inputs(num_samples=1)
Now, we can start the audio generation using the unconditional inputs:
audio_values = model.generate(**unconditional_inputs, do_sample=True, max_new_tokens=256)
The double asterisks ** before unconditional_inputs are used to unpack the dictionary unconditional_inputs and pass its contents as keyword arguments to the generate function. This provides the necessary input information for the model to generate audio.
The parameter do_sample=True indicates that during the generation process, the model should use a sampling strategy to select the following tokens (or, in this case, audio values). Sampling introduces randomness, which can result in more diverse and creative outputs.
Notice that we define max_new_tokens for generating the sound length. This parameter limits the length of the generated audio sequence. It specifies that the generated audio should contain a maximum of 256 new tokens (or audio values). This helps control the length of the output.
After executing these lines, the variable audio_values should contain the generated audio sequence stored in the tensor.
audio_values[:5]
tensor([[[-0.0305, -0.0327, -0.0313, ..., -0.0195, -0.0210, -0.0240]]],
device='cuda:0')
Use this to get the number of generated seconds:
audio_seconds = 256 / model.config.audio_encoder.frame_rate
audio_seconds
5.12
We can play the generated music in the Colab:
from IPython.display import Audio
sampling_rate = model.config.audio_encoder.sampling_rate
Audio(audio_values[0].cpu().numpy(), rate=sampling_rate)
An audio signal’s sampling rate (or sample rate) is the number of samples taken per second to represent the continuous analogue sound wave in a digital format. It is typically measured in Hertz (Hz). In my post Audio Signal Processing with Python’s Librosa, I describe usage of Python for working with audio files, their formats, spectral features and creating simple sound effects such as pitch shift and time stretch.
To save the model’s output into a WAV file, use Scipy:
# Saving to a WAV file
import scipy
scipy.io.wavfile.write("generated.wav", rate=sampling_rate, data=audio_values[0, 0].cpu().numpy())
Generating Music from Text Prompts
With AutoProcessor, we can feed in text prompts, such as defined by the ‘text’ list:
# An example of music generation from text prompts with transformers
from transformers import AutoProcessor
# Load the processor
processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
# List of text descriptions
text_list = [
# "Cinematic backdrop of reverberating piano, celestial strings, and ethereal flute"
# "Guitar-driven EDM with catchy synthesizer reverbs" # 7
# "Techno-dance futuristic music with deep bass and synth melodies" # 3
# "Techno-dance futuristic music with spiral, echo, deep bass and synth melodies" # 3
# "A lively jazz piano and sax piece with a playful melody and swinging rhythm" # used 6, 4 (excluded sax)
# "An ambient electronic track with silky bass guitar and ocean waves" # 6
# "An ambient electronic track with the sound of ocean waves" # 6
# "An ambient electronic track with the sound of ocean waves" # 4
"A symphonic poem of a fantasy adventure of elfs dancing in the magical forest" # 3 & 5
]
# Preprocess the text inputs
inputs = processor(
text=text_list,
padding=True,
return_tensors="pt",
)
audio_values = model.generate(**inputs.to(device), do_sample=True, guidance_scale=5, max_new_tokens=256*4)
Audio(audio_values[0].cpu().numpy(), rate=sampling_rate)
Finally, we can write the generated audio into a file, and download it.
scipy.io.wavfile.write("elfs_adventure_5gs_2.wav", rate=sampling_rate, data=audio_values[0, 0].cpu().numpy())
files.download('elfs_adventure_5gs_2.wav')
Notice that I have added a few prompts for you to start. You can experiment with different prompts to generate music samples of various genres:
- An ambient electronic track with ethereal textures and a gradual build-up
- A dramatic orchestral composition reminiscent of a fantasy adventure
- A catchy pop song with upbeat lyrics and a danceable beat
- A serene acoustic guitar piece with a calming melody, evoking a nature scene
- An energetic rock track with powerful guitar riffs and a driving tempo
- A futuristic techno tune with pulsating basslines and intricate synth patterns
- A romantic classical composition for a piano and violin duet
- An authentic country song with heartfelt lyrics and twangy guitar accompaniment
- An experimental avant-garde piece that blends unconventional sounds and rhythms
These prompts cover a variety of musical genres and can serve as starting points for generating music that aligns with different styles and moods. Create more prompts with chatGPT if you like.
I will soon add the Colab file with all the code, installation instructions, and more prompts. Keep reading :)
You can also experiment with guidance_scale parameter.
Classifier-free guidance guidance_scale defines the weighting between conditional logits predicted from the text prompt and the unconditional null prompt. Higher guidance_scale means poorer audio quality, however, favouring the text inputs.
Experimentally, I have found that the guidance_scale values from 3 to 7 give good results for the aforementioned text prompts and the small model.
Configuring the MusicGen Generation Process
We can configure the audio generation parameters. Nevertheless, default parameters are good to go. The model parameters that control audio generation are found in the generation_config:
model.generation_config
GenerationConfig {
"_from_model_config": true,
"bos_token_id": 2048,
"decoder_start_token_id": 2048,
"do_sample": true,
"guidance_scale": 3.0,
"max_length": 1500,
"pad_token_id": 2048,
"transformers_version": "4.32.0.dev0"
}
We can change any of these parameters.
# increase the guidance scale to 4.0
model.generation_config.guidance_scale = 4.0
# set the max new tokens to 256
model.generation_config.max_new_tokens = 256
# set the softmax sampling temperature to 1.5
model.generation_config.temperature = 1.5
When running the model, it uses these new settings. However, we define parameters in the model, and the defined parameter has higher priority than the specified in the model configuration. For instance, do_sample=False in the call to generate will take precedence over the setting of model.generation_config.
There is another configuration stored in the model.config:
model.config
MusicgenConfig {
"_name_or_path": "facebook/musicgen-small",
"architectures": [
"MusicgenForConditionalGeneration"
],
"audio_encoder": {
"_name_or_path": "facebook/encodec_32khz",
"add_cross_attention": false,
"architectures": [
"EncodecModel"
],
"audio_channels": 1,
"bad_words_ids": null,
"begin_suppress_tokens": null,
"bos_token_id": null,
"chunk_length_s": null,
"chunk_size_feed_forward": 0,
"codebook_dim": 128,
"codebook_size": 2048,
"compress": 2,
"cross_attention_hidden_size": null,
"decoder_start_token_id": null,
"dilation_growth_rate": 2,
"diversity_penalty": 0.0,
"do_sample": false,
"early_stopping": false,
"encoder_no_repeat_ngram_size": 0,
"eos_token_id": null,
"exponential_decay_length_penalty": null,
"finetuning_task": null,
"forced_bos_token_id": null,
"forced_eos_token_id": null,
"hidden_size": 128,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"is_decoder": false,
"is_encoder_decoder": false,
"kernel_size": 7,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"last_kernel_size": 7,
"length_penalty": 1.0,
"max_length": 20,
"min_length": 0,
"model_type": "encodec",
"no_repeat_ngram_size": 0,
"norm_type": "weight_norm",
"normalize": false,
"num_beam_groups": 1,
"num_beams": 1,
"num_filters": 64,
"num_lstm_layers": 2,
"num_residual_layers": 1,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_scores": false,
"overlap": null,
"pad_mode": "reflect",
"pad_token_id": null,
"prefix": null,
"problem_type": null,
"pruned_heads": {},
"remove_invalid_values": false,
"repetition_penalty": 1.0,
"residual_kernel_size": 3,
"return_dict": true,
"return_dict_in_generate": false,
"sampling_rate": 32000,
"sep_token_id": null,
"suppress_tokens": null,
"target_bandwidths": [
2.2
],
"task_specific_params": null,
"temperature": 1.0,
"tf_legacy_loss": false,
"tie_encoder_decoder": false,
"tie_word_embeddings": true,
"tokenizer_class": null,
"top_k": 50,
"top_p": 1.0,
"torch_dtype": "float32",
"torchscript": false,
"trim_right_ratio": 1.0,
"typical_p": 1.0,
"upsampling_ratios": [
8,
5,
4,
4
],
"use_bfloat16": false,
"use_causal_conv": false,
"use_conv_shortcut": false
},
"decoder": {
"_name_or_path": "",
"activation_dropout": 0.0,
"activation_function": "gelu",
"add_cross_attention": false,
"architectures": null,
"attention_dropout": 0.0,
"bad_words_ids": null,
"begin_suppress_tokens": null,
"bos_token_id": 2048,
"chunk_size_feed_forward": 0,
"classifier_dropout": 0.0,
"cross_attention_hidden_size": null,
"decoder_start_token_id": null,
"diversity_penalty": 0.0,
"do_sample": false,
"dropout": 0.1,
"early_stopping": false,
"encoder_no_repeat_ngram_size": 0,
"eos_token_id": null,
"exponential_decay_length_penalty": null,
"ffn_dim": 4096,
"finetuning_task": null,
"forced_bos_token_id": null,
"forced_eos_token_id": null,
"hidden_size": 1024,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_factor": 0.02,
"is_decoder": false,
"is_encoder_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layerdrop": 0.0,
"length_penalty": 1.0,
"max_length": 20,
"max_position_embeddings": 2048,
"min_length": 0,
"model_type": "musicgen_decoder",
"no_repeat_ngram_size": 0,
"num_attention_heads": 16,
"num_beam_groups": 1,
"num_beams": 1,
"num_codebooks": 4,
"num_hidden_layers": 24,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_scores": false,
"pad_token_id": 2048,
"prefix": null,
"problem_type": null,
"pruned_heads": {},
"remove_invalid_values": false,
"repetition_penalty": 1.0,
"return_dict": true,
"return_dict_in_generate": false,
"scale_embedding": false,
"sep_token_id": null,
"suppress_tokens": null,
"task_specific_params": null,
"temperature": 1.0,
"tf_legacy_loss": false,
"tie_encoder_decoder": false,
"tie_word_embeddings": false,
"tokenizer_class": null,
"top_k": 50,
"top_p": 1.0,
"torch_dtype": null,
"torchscript": false,
"typical_p": 1.0,
"use_bfloat16": false,
"use_cache": true,
"vocab_size": 2048
},
"is_encoder_decoder": true,
"model_type": "musicgen",
"text_encoder": {
"_name_or_path": "t5-base",
"add_cross_attention": false,
"architectures": [
"T5ForConditionalGeneration"
],
"bad_words_ids": null,
"begin_suppress_tokens": null,
"bos_token_id": null,
"chunk_size_feed_forward": 0,
"classifier_dropout": 0.0,
"cross_attention_hidden_size": null,
"d_ff": 3072,
"d_kv": 64,
"d_model": 768,
"decoder_start_token_id": 0,
"dense_act_fn": "relu",
"diversity_penalty": 0.0,
"do_sample": false,
"dropout_rate": 0.1,
"early_stopping": false,
"encoder_no_repeat_ngram_size": 0,
"eos_token_id": 1,
"exponential_decay_length_penalty": null,
"feed_forward_proj": "relu",
"finetuning_task": null,
"forced_bos_token_id": null,
"forced_eos_token_id": null,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_factor": 1.0,
"is_decoder": false,
"is_encoder_decoder": true,
"is_gated_act": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layer_norm_epsilon": 1e-06,
"length_penalty": 1.0,
"max_length": 20,
"min_length": 0,
"model_type": "t5",
"n_positions": 512,
"no_repeat_ngram_size": 0,
"num_beam_groups": 1,
"num_beams": 1,
"num_decoder_layers": 12,
"num_heads": 12,
"num_layers": 12,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"output_scores": false,
"pad_token_id": 0,
"prefix": null,
"problem_type": null,
"pruned_heads": {},
"relative_attention_max_distance": 128,
"relative_attention_num_buckets": 32,
"remove_invalid_values": false,
"repetition_penalty": 1.0,
"return_dict": true,
"return_dict_in_generate": false,
"sep_token_id": null,
"suppress_tokens": null,
"task_specific_params": {
"summarization": {
"early_stopping": true,
"length_penalty": 2.0,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
},
"temperature": 1.0,
"tf_legacy_loss": false,
"tie_encoder_decoder": false,
"tie_word_embeddings": true,
"tokenizer_class": null,
"top_k": 50,
"top_p": 1.0,
"torch_dtype": null,
"torchscript": false,
"typical_p": 1.0,
"use_bfloat16": false,
"use_cache": true,
"vocab_size": 32128
},
"torch_dtype": "float32",
"transformers_version": "4.32.0.dev0"
}
What are the differences between these two config classes? The model.config object is typically used when initialising a pre-trained model or creating a new instance of a specific model architecture. The model.generation_config stores the specific generation-related settings that the default model uses, as explained in the Text generation strategies.
Generating Music from Audio Inputs (Melody Continuation)
We can use audio inputs for generating sound sequences. For this:
- Load an audio input (we can use the datasets library of the HuggingFace);
- Use processor class to preprocess the audio, using the padding when the inputs have different lengths;
- Use the preprocessed audio as an input for the model generating sound;
- Enjoy your creation.
You can find HuggingFace datasets at https://huggingface.co/datasets. The most referred dataset is “sanchit-gandhi/gtzan” with blues, rock, classical and other genres, which is useful for genre classification tasks. See https://huggingface.co/datasets/sanchit-gandhi/gtzan/viewer/sanchit-gandhi–gtzan
This code loads a specific split (“train”) of the “sanchit-gandhi/gtzan” dataset. The streaming=True argument indicates that the dataset should be loaded in a streaming mode, which can be more memory-efficient for large datasets.
from datasets import load_dataset
dataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
sample = next(iter(dataset))["audio"]
Audio(sample["array"], rate=sample["sampling_rate"])
The next function to get the next element from the dataset. Since the dataset is loaded in streaming mode, this avoids loading the entire dataset into memory at once. The [“audio”] indexing is used to access the audio-related information “in the dataset, which likely includes the audio waveform array and its associated properties.
Is it possible to get dataset samples by genre?
# Let's check the dataset features
dataset.features
Yes, the genres are coded by integers. We will keep them in place and use their codes for getting the desired samples.
# Specify the genre you want to access (e.g., "blues" is the first genre encoded by 0)
desired_genre = 0 # "blues"
# Filter the dataset to get audio samples of the desired genre
samples_of_desired_genre = [sample for sample in dataset if sample["genre"] == desired_genre]
# Print the number of samples of the desired genre
print(f"Number of {desired_genre} samples:", len(samples_of_desired_genre))
Number of 0 samples: 100
Yes, its blues:
# Play the first audio sample of the desired genre
from IPython.display import Audio
sample = samples_of_desired_genre[0]["audio"]
Audio(sample["array"], rate=sample["sampling_rate"])
You can also create your audio dataset as explained at huggingface.
No, let’s use that blues sample audio to generate the “80s blues track”: You may observe how the beginning of the sequence resembles the original sample, especially when using the original text prompt. No wonder we use the “train” part of the dataset, which is not ideal.
# get the pre-trained model with the AutoProcessor
processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
# take the first quarter of the audio sample
sample["array"] = sample["array"][: len(sample["array"]) // 4]
inputs = processor(
audio=sample["array"],
sampling_rate=sample["sampling_rate"],
text=["80s blues"],
padding=True,
return_tensors="pt",
)
audio_values = model.generate(**inputs.to(device), do_sample=True, guidance_scale=5, max_new_tokens=256*4)
Audio(audio_values[0].cpu().numpy(), rate=sampling_rate)
Save the audio and download it:
scipy.io.wavfile.write("blues80s.wav", rate=sampling_rate, data=audio_values[0, 0].cpu().numpy())
files.download('blues80s.wav')
Downloading readme: 100% 703/703 [00:00<00:00, 44.0kB/s]
Batched audio generation with text prompts
Beforehand, we can check the RAM availability and delete the variables we do not need:
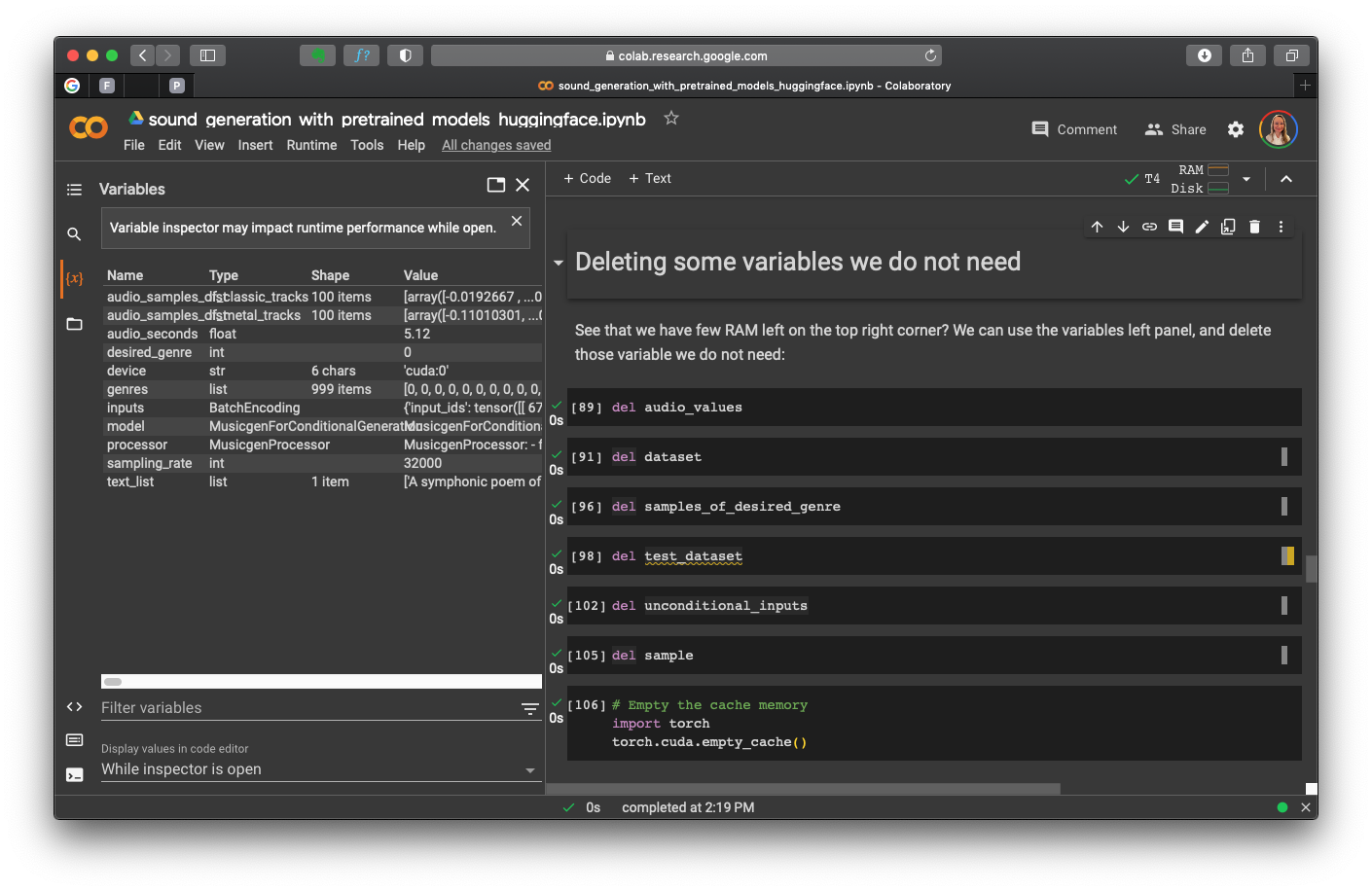
Colab, variables can be deleted
Imagine I want to use audio tracks of two different genres, classic and metal, for producing a new audio. That’s easy since we can also input several audio samples of different lengths.
For this, use the processor with padding=true. The inputs will be padded when necessary to the size of the longest audio sample. With processor.batch_decode, the generated audio can be post-processed to remove the padding.
Thus, I want to mix two different genres, classic and metal. Would it be fun? Let’s check.
First of all, let’s get the sample tracks that we can use as inputs:
# Classical music
audio_samples_of_classic_tracks = [sample for sample in dataset if sample["genre"] == 1]
# Listen to the first classic track
Audio(audio_samples_of_classic_tracks[0]["audio"]["array"], rate=sampling_rate)
# Metal
audio_samples_of_metal_tracks = [sample for sample in dataset if sample["genre"] == 6]
# Listen to the first metal track
Audio(audio_samples_of_metal_tracks[0]["audio"]["array"], rate=sampling_rate)
I like both track, lets use them for creating a mix:
# Import required functionality
from transformers import AutoProcessor, MusicgenForConditionalGeneration
# Create a processor
processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
inputs = processor(
audio=[audio_samples_of_classic_tracks[0]["audio"]["array"], audio_samples_of_metal_tracks[0]["audio"]["array"]],
sampling_rate=sampling_rate,
text=["Classic music", "A heavy metal track"],
padding=True,
return_tensors="pt",
)
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
audio_values = model.generate(**inputs.to(device), do_sample=True, guidance_scale=3, max_new_tokens=256*2)
# post-process to remove padding from the batched audio
audio_values = processor.batch_decode(audio_values, padding_mask=inputs.padding_mask)
Audio(audio_values[0], rate=sampling_rate)
I had to delete the unused variables with the dataset; however, I hit the RAM limitations. Interestingly, the model started to use all the available resources, which resulted in the message: “RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument index in method wrapper_CUDA__index_select)”
Please let me know if you managed to run this code. I had to restart my runtime to continue.
Music Generation with Meta’s Audiocraft
Yes, audio generation requires memory and time. I hope that you are well rested. Otherwise, prepare yourself a cap of your favourite drink. We will have to do something exciting.
Since you are reading this, you might continue using AI and Python code to generate audio files. And you must check the audiocraft GitHub repository to go deeper.
What is Audiocraft? Audiocraft, a deep learning audio processing and generation library, includes the advanced EnCodec audio compressor/tokenizer and MusicGen—an accessible music generation LM offering controllable output through textual and melodic conditioning.
We can use the MusicGen models in the Audiocraft, which can also be installed in Colab.
Firstly, we install the Audiocraft:
pip install -U audiocraft
Using MusicGen in Audiocraft
Audiocraft library has the MusicGen pre-trained melody model, you can find all models in their repository.
import torchaudio
from audiocraft.models import MusicGen
from audiocraft.data.audio import audio_write
model = MusicGen.get_pretrained('melody')
model.set_generation_params(duration=8) # generate 8 seconds.
descriptions = ['blues with double bass and saxophone', 'EDM music with sampler-sequencer, violin and drum machine', 'sad jazz']
wav = model.generate(descriptions) # generates 3 samples.
With torchaudio, we can get any audio file for extracting a melody from it. I will use an mp3 file with 32000 sampling rate from an mp3 file at espressif.com.
# Getting the file
!wget https://dl.espressif.com/dl/audio/ff-16b-2c-32000hz.mp3
When UTF-8 locale required, add these:
import locale
locale.getpreferredencoding = lambda: "UTF-8"
melody, sr = torchaudio.load('/content/ff-16b-2c-32000hz.mp3')
wav = model.generate_with_chroma(descriptions, melody[None].expand(3, -1, -1), sr)
for idx, one_wav in enumerate(wav):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness")
If you get the import error: “T5Tokenizer requires the SentencePiece library but it was not found in your environment…”, install it:
pip install sentencepiece
You can play your audio using the Audiocraft’s display_audio utility function:
from audiocraft.utils.notebook import display_audio
display_audio(one_wav, sample_rate=sr)
Continue sequence
We can continue the sequence (one_wav) generated by the last. We take the two seconds audio frame to continue: The “sr” variable is the sample rate.
seconds_number = 2
prompt = one_wav[:, -seconds_number*sr:]
We provide the descriptions input to get the desired result:
descriptions = ['sad jazz']
wav_continuation = model.generate_continuation(prompt, prompt_sample_rate=sr, descriptions=descriptions, progress=False)
display_audio(wav_continuation, sample_rate=sr)
# Compare with the original track:
display_audio(melody, sr)
Copyright and Licensing of AI-Generated Music
Copyright
Please notice that AI models are trained on existing sources, which might be copyrighted. Sound-alike AI-generated voices can also violate related artist rights.
Do you know about the song “Heart on my Sleeve”, published on TikTok and posted by Ghostwriter? The original audio was a deep fake and is now suspended.
I asked Google’s Bard what licence I should use for WAV files generated with MusicGen transformers and Python. Read what I got in response next in this section and in the “Licensing” section (slightly modified).
The legal status of AI-generated music, art, and derivative works must still be well-defined. It’s necessary to consult with legal experts who specialise in copyright and intellectual property law to get accurate guidance based on the latest legal developments in your jurisdiction. Rules and interpretations vary between countries. This is why think carefully when planning to profit from AI-generated tracks.
Licensing
The choice of a license for WAV files generated with MusicGen transformers and Python depends on a few factors, including the intended use of the files and the specific transformers used to create them. However, in general, the following licenses are commonly used for AI-generated music:
• Creative Commons Attribution-Noncommercial-Share Alike 4.0 International (CC BY-NC-SA 4.0): This is a permissive license that allows for the free use, distribution, and modification of the files, as long as attribution is given to the original creator and the files are not used for commercial purposes.
• The Unlicense: This license waives all copyright and related rights to the files. This means anyone can use, distribute, and modify the files without restrictions.
• The GNU General Public License (GPL): This is a copyleft license that requires that any derivative works of the files be licensed under the GPL. If you use the files to create new music, you must also make your new music available under the GPL.
Ultimately, the best license for your WAV files is the one that best suits your needs and goals. If you are unsure which license to choose, consider consulting with an attorney.
In addition to choosing a license, it is also essential to consider the following factors when releasing WAV files generated with MusicGen transformers and Python:
• Attribution: Always give attribution to the original creator of the transformer models and the Python code used to generate the files. This will ensure that your work is appropriately credited and that others can find the code and models if they want to use them.
• Noncommercial Use: If you use a license that restricts commercial use, such as CC BY-NC-SA 4.0, make it clear that your WAV files are not intended for commercial use. You may also want to include a statement that you will not tolerate the commercial use of your files without your permission.
• Modification: If you use a license that allows modification, such as CC BY-SA 4.0, be aware that others may modify your files and release their own versions. This is perfectly legal, but it is important to be mindful of the possibility and prepared to respond to any issues.
By following these guidelines, you can ensure that your WAV files generated with MusicGen transformers and Python are used responsibly and ethically.
Try the following fantastic AI-powered applications.
I am affiliated with some of them (to support my blogging at no cost to you). I have also tried these apps myself, and I liked them.
ElevenLabs.io creates fantastic and realistically sound AI voices.
mubert generates high quality royalty-free music for any platform.
Murf.AI generates voice from text prompts, and much more in respect to voice synthesis.
Play.ht can generate voice from text prompts, creates audio embeddings and play buttons for WordPress or any web page, podcast creation, and much more in respect to voice synthesis.
Speechify synthesises great-quality voice from text.
Conclusion: Tools for Generating Music with AI
AI-generated music opens up a realm of creativity. We can craft music for podcasts, social media, and various applications with impressive AI generators. Developing our code using pre-trained models and Python opens up even more possibilities. HuggingFace Transformers with MusicGen is a Python toolkit for generating music from text prompts or audio inputs using pre-trained models.
Thanks
I thank Google for providing the computation resources in Colab and HuggingFace researchers and developers for sharing the repository and related documentation.
AI Music Generation FAQ
Which Python library generates music from a text prompt?
HuggingFace Transformers with Meta’s MusicGen model generates audio from text. Install it with pip install transformers, load the processor and model, pass a text description, and call model.generate().
Can MusicGen continue or extend an existing melody?
Yes. MusicGen supports melody conditioning: you provide an audio sample as input alongside (or instead of) a text prompt, and the model generates a continuation that follows the supplied melody.
Do I need a GPU to generate music with MusicGen?
A GPU is not strictly required, but it greatly speeds up generation. The code selects accelerator hardware when available and falls back to CPU otherwise; Google Colab provides a free GPU runtime that works well.
Is music generated with MusicGen free to use commercially?
It depends on the model’s license and the data it was trained on. AI-generated music can fall under licenses such as CC BY-NC-SA 4.0, and the legal status of derivative works varies by jurisdiction — consult the model license and, for commercial use, a legal expert.
Did you like this post? Please let me know if you have any comments or suggestions.
These posts might be interesting for youReferences
- OpenAI’s Jukebox library
- Aiva 3. mubert
- ecrettmusic.com
- riffusion
- Soundful
- you can find all models in their repository
- beatoven.ai
- orbplugins.com
- an mp3 file at espressif.com
- MusicGen.ipynb
- Audio Signal Processing with Python’s Librosa
- GitHub repository
- MusicGen: Simple and Controllable Music Generation
- YouTube, Orb plugins
- Magenta Studio
- Demos
- VOCALOID
- MusicGen
- huggingface
- repository folder
- Text generation strategies
- beatbot.fm
- Country music made with Jukebox
- artificial neural networks
- evokemusic.ai
- notebooks
- audiocraft
- demo webpage
- evokemusic.ai offers a collection of audio files
- Sanchit Gandhi, a researcher at HuggingFace
- Boomy.com
- Bard
Enjoyed this? Get more like it.
Weekly notes on AI tools, Python, and what I'm actually building — plus two free gifts: the 15-page Fantastic AI: The 2026 Toolkit and a Git Commands & Contribution Workflow Cheatsheet.
