
Introduction: AI Voice Synthesis and Cloning
In this post, I discuss voice synthesis and cloning, and mention fantastic AI tools and APIs for creating high-quality human-like voices from text or for automatic voice dubbing.
What Is Voice Synthesis?
Voice synthesis is a broad term encompassing various techniques for converting text into speech. TTS (Text to Speech) is a common form of voice synthesis that converts written text into spoken audio.
Voice cloning is a sophisticated technique that employs machine learning to generate a digital copy of a person’s voice. This technology can create highly realistic voice recordings that can be utilized in several applications including audiobooks, video games, and even phone calls.
Here are some other examples of voice synthesis techniques:
-
Paralinguistics: This technique adds extra information to speech, such as emotion, emphasis, and tone of voice. This can be used to create more natural and engaging audio recordings.
-
Voice conversion: This technique converts speech from one voice to another. This can create more diverse voices for video game characters or provide voiceovers for non-native speakers.
-
Voice synthesis with deep learning: This newer technique uses deep learning to create more realistic and natural-sounding speech. This can be utilized to create realistic voice actors for video games or provide more engaging audio experiences for e-learning platforms.
This can be used to create more realistic voice actors for video games or provide engaging audio experiences for e-learning platforms.
Text-to-Speech (TTS) Explained
Voice generation is creating artificial or synthetic human-like voices using technology. This can involve the use of various techniques, such as text-to-speech systems that transform written text into spoken words.
These systems often employ machine learning and natural language processing algorithms to generate increasingly natural and expressive voices.
TTS usage
Text-to-speech (TTS) technology is widely used in various applications to generate synthetic voices. Here are five applications that leverage TTS for different purposes:
- Accessibility Tools:
- Purpose: TTS is extensively used in accessibility tools to assist individuals with visual impairments. It converts written text into spoken words, enabling users to consume digital content like websites, documents, or messages.
- Example: Screen readers, which provide auditory feedback to users navigating through digital interfaces, use TTS to read aloud text on the screen.
- Navigation Systems:
- Purpose: In-car navigation systems and GPS applications use TTS to provide turn-by-turn directions audibly. This helps drivers concentrate on the road without needing to glance at the screen for guidance.
- Example: Google Maps or other navigation apps that verbally guide users during a journey.
- Virtual Assistants:
- Purpose: TTS is a fundamental component of virtual assistants and chatbots. It allows these AI-driven interfaces to communicate with users by converting text-based responses into spoken language.
- Example: Voice-activated virtual assistants like Amazon Alexa, Google Assistant, or Apple’s Siri use TTS to respond to user queries verbally.
- E-Learning Platforms:
- Purpose: TTS enhances the learning experience in online education platforms by converting written content into spoken words. This is beneficial for learners who prefer auditory learning or have reading difficulties.
- Example: Educational apps or platforms that offer audio versions of textbooks or provide spoken explanations for course materials.
- Podcast and Media Production:
- Purpose: TTS can be employed in media production to generate synthetic voices for narration or character dialogues. This can save time and resources in audio content creation.
- Example: Podcast producers or video creators may use TTS technology to voice specific content segments or generate character voices in animations.
These applications showcase the versatility of TTS technology in improving accessibility, user experience, and content creation across various domains.
TTS applications
Many AI applications provide Text-to-Speech (TTS) and speech synthesis capabilities. We will shortly introduce several production-level applications and APIs that can be used today.
The most used TTS app depends on the platform and the user’s preferences. However, some of the most popular TTS apps include:
Speechify is a premium TTS app with advanced features like reading web pages and PDFs. Speechify is very helpful for tutors and in educational settings. It provides more than 50 human-like voices in 15 languages today.
TTSReader enables natural-sounding voices from different accents for a superior listening experience.
[Voice Aloud Reader] is a tremendous free text-to-speech Android app that shows ads on the screen, which can removed for $10.
Voice Dream has more than 200 AI voices that you can use to read PDFs, articles, e-books, web pages, and anything else, even without an Internet connection.
Balabolka is a popular free and open-source TTS app with many features and excellent text-to-WAV conversion.
TextAloud is a lightweight TTS app with various voices. Their “NextUp Talker” is a Text to Speech program specifically designed for people who have lost their voice to assist in communicating with others using a Windows PC or Tablet PC.
TTS APIs
Google Cloud Text-to-Speech API
Google Cloud Text-to-Speech API is a cloud-based service that converts text into natural-sounding speech using Google’s advanced machine learning technology. It allows developers to integrate lifelike speech synthesis into their applications. The API offers a wide range of features, including:
-
High-quality speech: The API produces high-fidelity speech almost indistinguishable from human speech. It can handle a wide range of accents, dialects, and languages.
-
Wide range of voices: Users can choose from over 380 voices across 50 languages and variants. This allows developers to create applications in the user’s preferred language and accent.
-
Customizable voices: Developers can create custom voices using Speech Synthesis Markup Language (SSML). This allows them to control the speech’s pitch, tone, and speed and add effects such as emphasis and pauses.
-
Real-time speech synthesis: The API can synthesize speech in real-time, which makes it ideal for applications that require speech to be generated on demand.
-
Cross-platform compatibility: The API is compatible with various Android, iOS, web, and desktop platforms.
-
Easy to use: The API is easy to use and integrates seamlessly with other Google Cloud services.
Here are some of the use cases for Google Cloud Text-to-Speech API:
-
E-books and audiobooks: The API can be used to create audiobooks and e-books that read aloud to the user.
-
Interactive learning applications: The API can create interactive learning applications that use speech to deliver lessons and feedback.
-
Voice assistants: The API can power voice assistants to answer questions, provide information, and control devices.
-
Accessibility features: The API can create accessibility features that make it easier for people with disabilities to use applications.
-
Marketing and advertising: The API can create marketing and advertising campaigns that use speech to engage users.
Overall, Google Cloud Text-to-Speech API is a powerful tool to create various applications with lifelike speech capabilities. It is a valuable addition to the Google Cloud platform and will be used by developers worldwide.
Amazon Polly
Amazon Polly is a cloud-based service from Amazon Web Services (AWS) that converts text into human-like speech. It provides various features that make it easy for developers to integrate speech synthesis into their applications.
Key features of Amazon Polly:
-
High-quality speech: Amazon Polly uses advanced deep learning technology to produce natural-sounding speech almost indistinguishable from human speech.
-
Wide range of voices: Amazon Polly offers a variety of voices, each with its unique personality and accent. Developers can choose from dozens of voices across a broad set of languages.
-
Customizable voices: Developers can customize the voices used by Amazon Polly using Speech Synthesis Markup Language (SSML). This allows them to control the speech’s pitch, tone, and speed and add effects such as emphasis and pauses.
-
Real-time speech synthesis: Amazon Polly can synthesize speech in real-time, making it ideal for applications that require speech to be generated on demand.
-
Cross-platform compatibility: Amazon Polly can synthesise speech for various platforms, including Android, iOS, web, and desktop.
-
AWS integration: Amazon Polly integrates seamlessly with other AWS services, such as Amazon S3, Amazon Lex, and Amazon SageMaker.
Common use cases for Amazon Polly:
-
Creating audiobooks and e-books: Amazon Polly can be used to create audiobooks and e-books that read aloud to the user.
-
Developing voice assistants: Amazon Polly can power voice assistants to answer questions, provide information, and control devices.
-
Generating synthetic speech for games: Amazon Polly can generate synthetic speech for game characters, making them more engaging and immersive.
-
Creating educational content: Amazon Polly can be used to create educational content that is more engaging and accessible for visually impaired users.
-
Developing marketing and advertising campaigns: Amazon Polly can create marketing and advertising campaigns that use speech to engage users.
Overall, Amazon Polly is a powerful and versatile tool that can create various applications with speech synthesis capabilities. It is a valuable addition to the AWS ecosystem and will be used by developers of all skill levels.
If interested, check their Python, Java, iOS, and Android example applications at Example Applications.
Microsoft Azure Text to Speech
Microsoft Azure Text-to-Speech API is a cloud-based service that converts text into lifelike, natural-sounding speech. It leverages Microsoft’s cutting-edge AI technology to produce high-fidelity speech resembling human voices. Developers can utilize this API to seamlessly integrate lifelike speech synthesis into their applications.
Key Features of Microsoft Azure Text-to-Speech API:
-
High-Quality Speech: The API generates high-quality speech nearly indistinguishable from human speech. It handles various accents, dialects, and languages, ensuring natural and engaging audio output.
-
Extensive Voice Selection: Developers can access diverse voices with unique personalities and accents. Choose from over 30 voices across 28 languages and locales to match the specific needs of your application.
-
Custom Voice Creation: Leverage Speech Synthesis Markup Language (SSML) to create custom voices tailored to your brand or application’s requirements. Fine-tune pitch, tone, and speed, and add effects like emphasis and pauses to achieve the desired auditory experience.
-
Real-time Speech Synthesis: Generate speech in real-time, enabling applications that require speech to be generated on demand, such as live virtual assistants or interactive learning experiences.
-
Cross-Platform Compatibility: Utilize the API across various platforms, including Android, iOS, web, and desktop, ensuring consistent speech synthesis irrespective of the user’s device or environment.
-
Seamless Integration: Seamlessly integrate the API with other Microsoft Azure services, such as Azure Cognitive Services, Azure IoT Hub, and Azure Bot Service, for enhanced application capabilities and scalability.
Common Use Cases for Microsoft Azure Text-to-Speech API:
-
Interactive Learning Applications: Enhance learning experiences by providing audio narration for text content, making tutorials and presentations more engaging and accessible.
-
Voice Assistants: Power voice assistants with the ability to read aloud, provide information, and interact with users naturally, mimicking human-like conversations.
-
Accessibility Features: Implement accessibility features that read aloud text content for visually impaired users, ensuring inclusive and equitable access to information.
-
E-books and Audiobooks: Create engaging e-books and audiobooks that read aloud the content, enhancing user experience and comprehension.
-
Marketing and Advertising Campaigns: Utilize the API to create personalized and engaging marketing campaigns that use speech to capture audience attention and deliver tailored messages.
Microsoft Azure Text-to-Speech API is a powerful tool for developers seeking to incorporate lifelike speech synthesis into their applications. Its versatility, advanced features, and cross-platform compatibility make it valuable for many use cases.
AI Voice Cloning
Voice cloning, on the other hand, involves creating a replica or copy of a specific person’s voice. This is done by recording and analyzing a person’s speech patterns, intonations, and other vocal characteristics and then using this data to generate a synthetic voice that mimics the original person’s speech. Voice cloning technology has various potential applications, such as voice assistants, virtual avatars, and entertainment.
Ethical concerns
It’s important to note that while these technologies offer various benefits, including accessibility and improved user experiences, they also raise ethical concerns. In particular, voice cloning can be misused for fraudulent activities, such as creating fake audio recordings that impersonate individuals. As a result, ongoing research and development in the field addresses both the positive and negative implications of voice generation and cloning technologies.
Copyright
The legal status of voice cloning is still evolving, and there needs to be a clear consensus on who owns the copyright to a cloned voice. However, a few factors suggest that the copyright may belong to the person whose voice is being cloned.
-
Copyright law protects original works of authorship. A cloned voice is a unique creation that is not simply a copy of another voice. It is a derivative work created using machine learning algorithms to analyze and replicate the original voice.
-
Copyright law protects against unauthorized use of a person’s likeness. A cloned voice can be used to create a convincing impersonation of a person. This could be used to defame or impersonate the person or to create a false impression of the person’s endorsement of a product or service.
-
Privacy rights protect a person’s control over their own likeness. A cloned voice can create a deepfake, a synthetic video or audio recording manipulated to make it appear as if a person is saying or doing something that they did not actually say or do. Deepfakes can be used to spread misinformation or damage a person’s reputation.
In light of these factors, it is reasonable to argue that the copyright to a cloned voice should belong to the person whose voice is being cloned. This would help protect the person’s privacy and prevent their likeness from being used in a way they would disapprove of.
However, there are also some arguments in favour of the developer of the AI app owning the copyright to the cloned voice. These arguments include the following:
-
The developer invested time and resources in creating the AI app. The app is a valuable piece of software that can be used to create realistic and convincing voice clones.
-
The developer owns the copyright to the underlying software code that powers the AI app. This code is essential to the creation of voice clones.
-
The developer should be able to reap the rewards of their invention. The developer deserves to be compensated for their work in creating a technology that has the potential to revolutionize the way we interact with voice-based interfaces.
Ultimately, the question of who owns the copyright to a cloned voice is likely to be decided by the courts. However, the arguments for both sides of the issue are compelling, and the courts will likely need to carefully balance the competing interests of copyright protection, privacy rights, and the free flow of ideas.
In the meantime, individuals considering using AI apps to clone their voices should be aware of the potential legal and ethical implications of their actions. They should also consult with an attorney to discuss their specific circumstances.
You can publish AI-generated sounds and voices online on YouTube or other web platforms. The legal and ethical implications of doing so are still being debated, but there needs to be a clear consensus on whether or not it is permissible.
Legal Implications:
The legal implications of publishing AI-generated sounds and voices online are complex and nuanced. In general, copyright law protects original works of authorship. However, it is still being determined whether AI-generated sounds and voices are considered original works of authorship.
Some argue that AI-generated sounds and voices are not original works of authorship because they are created using machine learning algorithms, which are not inherently creative. Others say that AI-generated sounds and voices are original works of authorship because they result from human creativity, even though the sounds and voices themselves are created by machines.
There is no clear legal precedent on this issue, so it is unclear whether or not you could be sued for copyright infringement if you publish AI-generated sounds and voices online.
Ethical Implications:
The ethical implications of publishing AI-generated sounds and voices online are complex and nuanced. Some argue that it is unethical to publish AI-generated sounds and voices without disclosing that they are AI-generated because this could deceive listeners into thinking that the sounds and voices are created by humans.
Others argue that it is not unethical to publish AI-generated sounds and voices without disclosing that they are AI-generated, as long as the sounds and voices are not used in a harmful or misleading way.
Ultimately, whether or not to publish AI-generated sounds and voices online is a personal decision. You should weigh the potential legal and ethical implications carefully before deciding.
YouTube Policy:
YouTube’s policy on AI-generated content needs to be clarified. The company has a policy against “synthetic media” used to “harm, deceive, or defraud.” Still, it is being determined whether or not AI-generated sounds and voices would be considered synthetic media.
Other Web Platforms:
The policies of other web platforms on AI-generated content may vary. It is essential to check the policies of the specific platform you want to publish your AI-generated content.
Here are some additional things to consider:
- The purpose of your AI-generated content. Are you using AI-generated sounds and voices to create art, music, or other creative works? Or are you using them to deceive or mislead others?
- The potential impact of your AI-generated content. Could your AI-generated content harm or deceive others? Or could it be used to spread misinformation or propaganda?
By considering these factors, you can make an informed decision about whether or not to publish AI-generated sounds and voices online.
AI apps for voice cloning and TTS
Next, let’s explore practical AI applications that are available today.
Play.ht
Play.ht is a cloud-based TTS platform that offers a wide range of features, including over 60 high-quality voices, multiple languages, and advanced customization options.
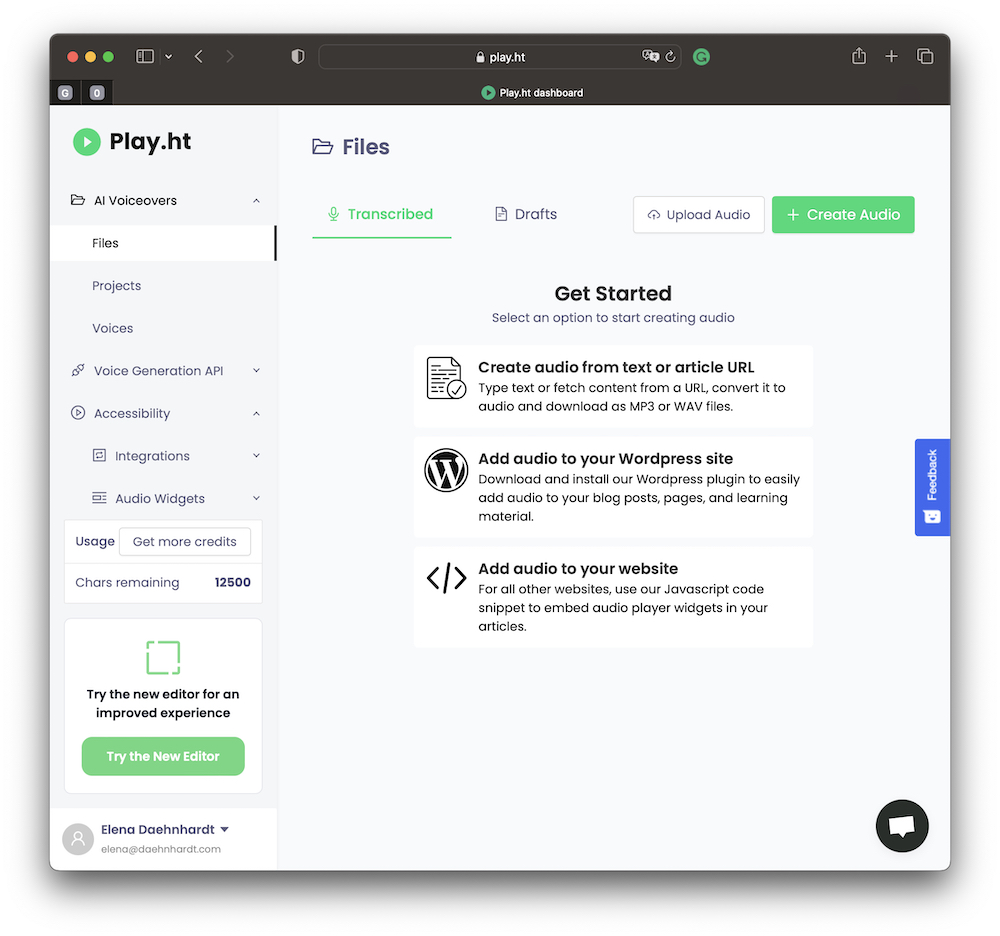
Play.ht Web Interface
Play.ht is particularly well-known for its voice cloning capabilities, which allow users to create realistic and lifelike AI voices based on existing audio recordings.
Play.ht also offers a variety of other features, such as text-to-music generation, podcast creation, voice embedding for web pages, audio widgets, and audio editing tools.
I love this voice embedding feature provided by Play.ht.
Murf AI
Murf.AI is a cloud-based TTS platform that focuses on creating engaging and professional audio content. The platform offers over 20 natural-sounding voices, multiple languages, and a variety of audio editing tools.
Murf.AI is particularly well-suited for creating presentations, e-learning materials, and other types of audio content that require professional quality. The platform also offers a freemium plan that allows users to generate up to 10,000 text characters per month (see all plans at: Murf.AI ).
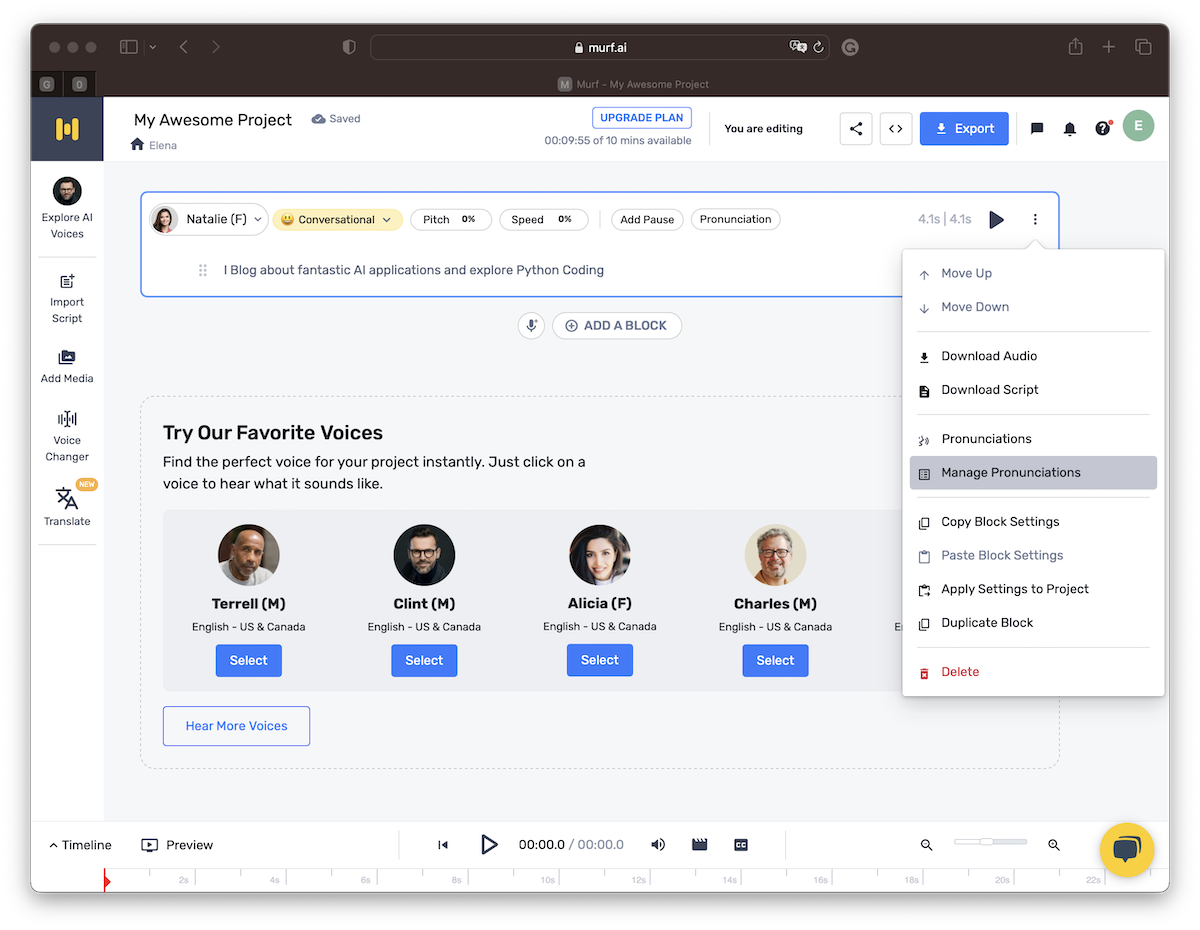
Murf.AI Web Interface
ElevenLabs
ElevenLabs.io is a leading provider of artificial intelligence (AI)-powered text-to-speech (TTS) technology. The company’s innovative platform enables users to generate high-quality, natural-sounding speech from any written text in over 29 languages.
In addition to these options, several other TTS and voice cloning platforms are available. The best option for you will depend on your specific needs and requirements.
I will use ElevenLabs.io to demonstrate voice cloning and TTS next. Please notice that I am affiliated with them. It is free, but you will support my blogging if you use an ElevenLabs paid subscription.
ElevenLabs features include:
- Free Text-to-Speech API: A free API that allows anyone to convert text into lifelike audio in minutes.
- Premium Text-to-Speech: A paid service that offers more advanced features, such as custom voice creation, language-specific voices, and dubbing capabilities.
- AI Voice Generator: A tool that allows users to create personalized AI voices with unique characteristics, such as gender, age, and accent.
ElevenLabs’ technology is used by a wide range of businesses and individuals, including:
- Content creators: YouTubers, podcasters, and others use ElevenLabs to create engaging audio content without traditional recording.
- E-learning platforms: Educational institutions and e-learning companies use ElevenLabs to provide interactive and accessible learning experiences.
- Accessibility solutions: Organizations that provide accessibility solutions to people with disabilities use ElevenLabs to create audio summaries of written content.
ElevenLabs has been recognized for its innovative TTS technology and is considered one of the leading companies in the AI Spring. The company is committed to advancing the state of the art in TTS technology and is constantly pushing the boundaries of what is possible.
Here are some of the key features of ElevenLabs’ TTS technology:
- Natural-sounding speech: ElevenLabs’ voices are indistinguishable from human speech, thanks to its advanced AI algorithms.
- Contextual understanding: ElevenLabs’ AI can understand the context of the text and generate speech appropriate to the content.
- Emotional capabilities: ElevenLabs’ voices can convey a wide range of emotions, making them suitable for various applications.
If you are looking for a powerful and versatile TTS solution, ElevenLabs is an excellent option. With its wide range of features and support for over 29 languages, ElevenLabs can help you create engaging and accessible audio content for any purpose.
Subscriptions
ElevenLabs.io offers a free version, but it has limited features compared with the paid version, providing up to 10000 characters per month for text-to-speech conversion in the free version.
Speech Synthesis
ElevenLabs.io’s speech synthesis has two main features: 1. Text-to-speech for converting from text to voice; 2. Speech-to-speech for transforming your voice file into your voice of choice.
Both features have a great set of “premade” voices, with adjustable settings in voice stability (lower stability can lead to monotonously sounded voices), voice clarity, style exaggeration (as compared to the uploaded audio), and speaker boost.
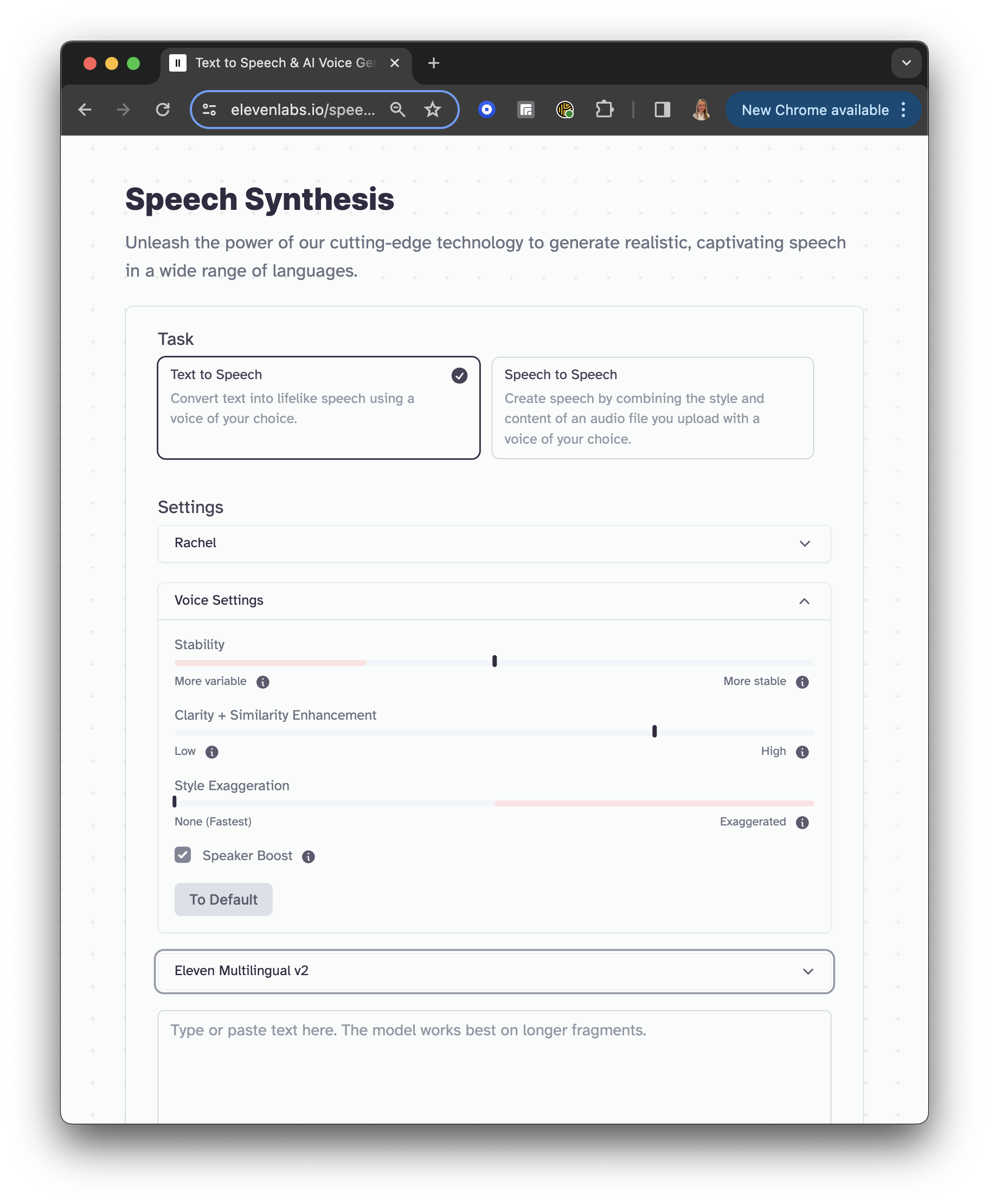
ElevenLabs Speech Synthesis
You must choose a voice, its stability (voice expressiveness) or other parameters, type in your text input, and click “Generate”. Listen to the generated voice, and you can download it.
A different voice variation will be applied if you do not change the text, but press Generate again.
Besides various English accents, ElevenLabs.io can generate speech in 28 more languages in the Eleven Multilingual v2, while v1 supports 9 languages including English.
Converting text to speech is done very accurately. If you choose one of the 100s of voices available in the app, the quality of the output is fantastic. The interface is straightforward to use.
Dubbing
You can automatically create voice content in other languages with voice dubbing.
VoiceLab
In VoiceLab, you can clone your own voice (or a voice you’re allowed to use) or make brand-new computer voices.
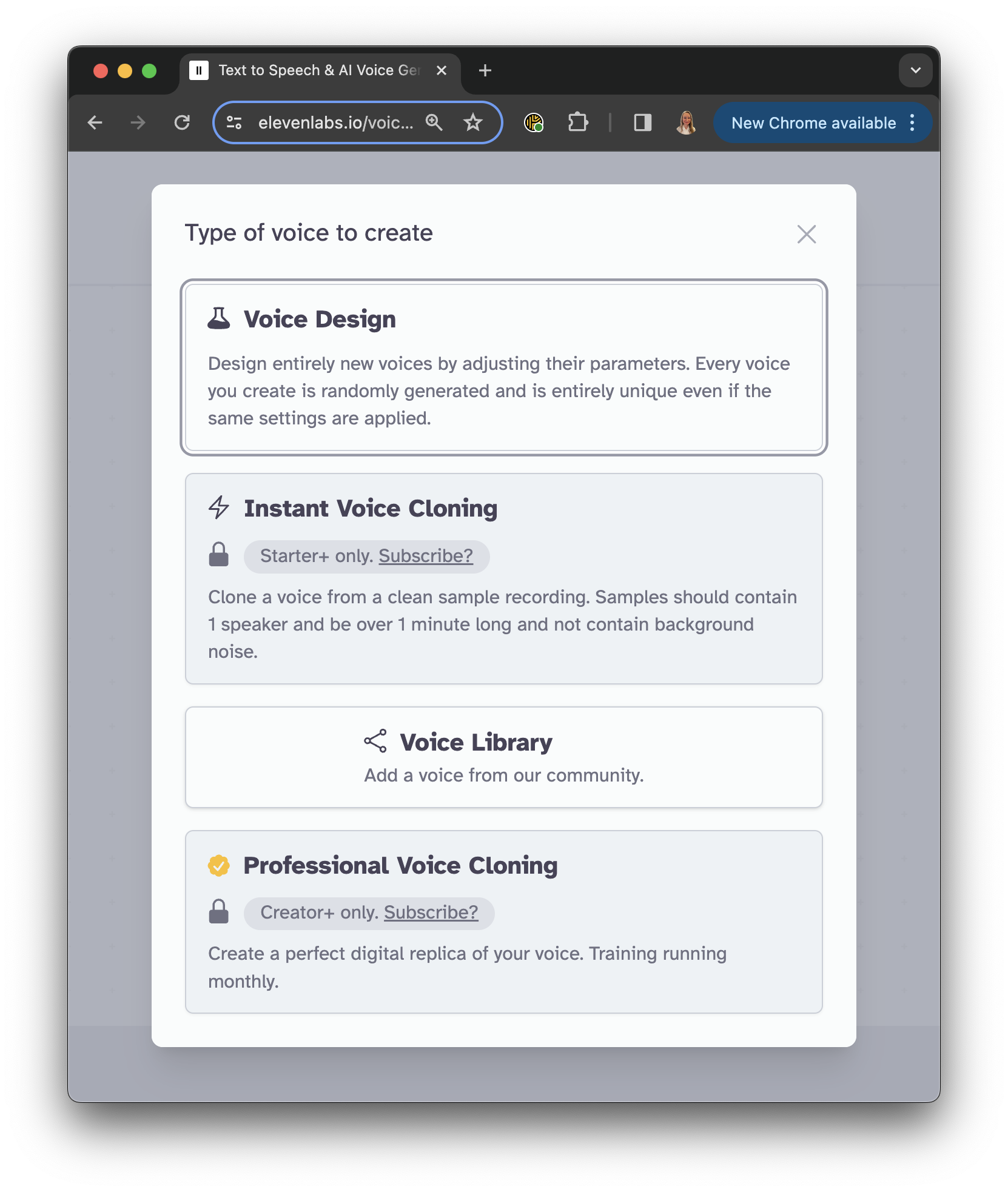
ElevenLabs VoiceLab
You can create voice design for new voices by adjusting their parameters (gender, age, accent and strength) and save the created voice for further use in the Speeech Synthesis section or download it later.
To create voice clones, you must use well-recorded quality voice samples. Professional voice cloning is only available for Creator+ subscriptions.
Alternatively, you can explore voices created by the community.
Potential Risks of AI Voice Cloning
While this technology has various legitimate and beneficial applications, such as voice assistants, dubbing, and entertainment, it can also be misused.
Thank you very much, Alex, for your always thoughtful feedback and suggestions.
Voice cloning technology poses risks to identity theft and security. Here are some potential risks associated with voice cloning and its impact on identity theft:
-
Impersonation: A malicious actor could use voice cloning to impersonate someone and attempt to deceive others, such as gaining unauthorised access to sensitive information, committing fraud, or manipulating individuals into specific actions.
-
Social Engineering Attacks: Voice cloning could be used in social engineering attacks where the attacker mimics the voice of a known and trusted person to manipulate others into providing confidential information or performing actions they wouldn’t otherwise do.
-
Phishing Calls: Voice cloning could be employed in phishing calls, making it more challenging for individuals to distinguish between genuine and fraudulent calls.
-
Fraudulent Transactions: Voice cloning might be used to authorise financial transactions or access secure systems by mimicking an authorised user’s voice.
To mitigate these risks, individuals and organisations need to be aware of the capabilities of voice cloning technology and take appropriate security measures:
-
Authentication Methods: Implement multi-factor authentication and other robust authentication methods to enhance security beyond voice recognition.
-
Awareness Training: Educate individuals about the potential risks of voice cloning and teach them to be cautious about providing sensitive information based solely on voice instructions.
-
Monitoring and Detection: Employ technologies that can detect anomalies in voice patterns or other behavioural cues to identify potentially fraudulent activities.
-
Regulation and Compliance: Advocate for and comply with regulations related to the ethical use of voice cloning technology. Governments and organisations may implement policies to ensure responsible and lawful use.
As technology continues to advance, both developers and users must stay informed about potential risks and safeguards to prevent misuse.
Conclusion: Choosing AI Voice Tools
This post discussed speech synthesis, voice cloning, text-to-speech applications and APIs available today. We considered ethical and copyright ownership of the AI-generated voice clones. We explored voice synthesis and cloning with AI applications such as ElevenLabs.io, Play.ht
AI Voice Synthesis FAQ
What is the difference between text-to-speech and voice cloning?
Text-to-speech (TTS) converts written text into spoken audio using a generic synthetic voice. Voice cloning uses machine learning to build a digital copy of a specific person’s voice, so the generated speech sounds like that individual.
Which cloud APIs offer text-to-speech?
The major options are Google Cloud Text-to-Speech, Amazon Polly, and Microsoft Azure Text to Speech. Each provides many languages and neural voices and is billed per character or per million characters synthesised.
Which AI apps are best for voice cloning?
Popular voice-cloning and TTS apps include ElevenLabs, Play.ht, Murf AI, and WellSaid Labs. ElevenLabs is widely used for highly natural cloned voices and multi-language dubbing.
Is AI voice cloning legal and ethical?
Cloning a real person’s voice without consent can infringe personality and copyright rights and enable impersonation fraud. Use voice cloning only with explicit permission, and disclose synthetic audio where appropriate.
Did you like this post? Please let me know if you have any comments or suggestions.
These posts might be interesting for youRelated tools you may want to try next.
Pictory.ai creates professional quality videos from your script with realistic AI voices, matching footage and music in a few clicks. Pictory.AI can also convert blog posts into captivating videos and extract highlights from your recordings to create branded video snippets for social media, and much more.
References
1. Google Cloud Text-to-Speech API
3. Example Applications (using Polly)
4. Microsoft Azure Text to Speech API
8. Voice Cloning Guide: How to use our technology safely and follow best practice
Enjoyed this? Get more like it.
Weekly notes on AI tools, Python, and what I'm actually building — plus a free copy of Fantastic AI: The 2026 Toolkit.
