Introduction
In 2020, Facebook AI (now Meta AI) introduced Retrieval-Augmented Generation (RAG) to improve the accuracy of generated text by combining retrieval-based and generative models, read Retrieval Augmented Generation: Streamlining the creation of intelligent natural language processing models. RAG has since become fundamental for improving language model performance in scenarios requiring creativity and factual accuracy.
The FAIR (Facebook AI Research) group primarily led the research, including notable researchers such as Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, and others. You can read their paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks(2020) explaining their approach to handling tasks like open-domain question answering, where grounding responses in real, up-to-date data is crucial for accuracy.
Accordingly to Lewis, P. et al. (2020) in Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2020), RAG is preferred over purely parametric models for being more factual and specific.
However, the possibility of hallucination in RAG systems should not be underestimated, see Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools. The AI legal research tools like Lexis+ AI and Westlaw sometimes provide misleading or false information in response to queries 3
If interested about the AI hallucinations, their implications in various domains and possible remedies, read my post Can AI Hallucinate?
What is Retrieval-Augmented Generation?
RAG is an advanced AI technique that combines generative models with retrieval mechanisms to create content in a unique way. RAG pulls in external information before generating accurate and relevant content.
RAG addresses the limitations of purely generative models, such as hallucinations and contextually inaccurate outputs, making it a vital technique for applications requiring high precision and reliability.
How RAG Works
RAG employs a two-step process involving a retriever and a generator. The retriever identifies relevant documents or data based on the input query, and the generator uses this retrieved information to produce a coherent and accurate response.
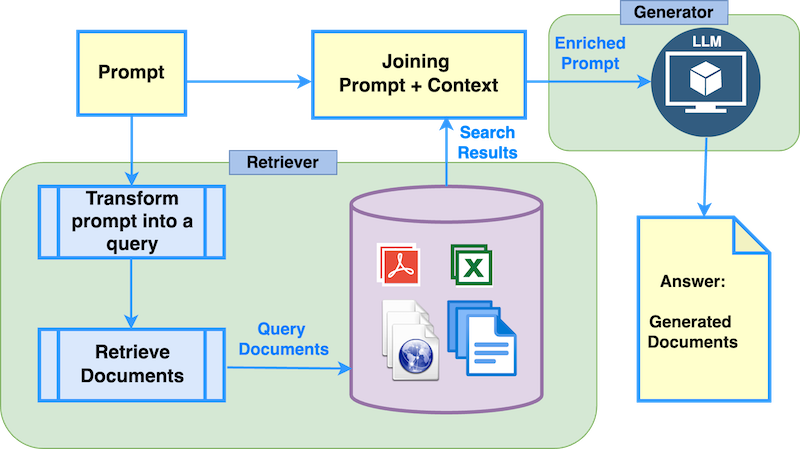
The main steps in the RAG Process include the following:
- Prompt Input: The user inputs a prompt.
- Retrieval: The user prompt is transformed into a query format that allows the retriever to search a large corpus for relevant documents. We can use text files, PDF documents, and any file formats or records used for a particular RAG implementation. The documents can include any information, such as product or service descriptions.
- Augmentation: Augmentation occurs when we combine the user prompt and context information. The retrieved documents are combined with the input query.
- Generation: The generative model produces a response using the augmented input.
3 Key Differences of RAG and GenAI
- Information Source:
- Generative AI: Relies solely on patterns learned from its training data.
- RAG: Uses external sources or databases to retrieve relevant information before generating content.
- Accuracy and Relevance:
- Generative AI: May produce content based on outdated or incomplete information if it hasn’t been trained on the most current data.
- RAG: Produces more accurate and contextually relevant content by incorporating up-to-date information through retrieval. However, RAG still can hallucinate 2.
- Complexity:
- Generative AI: Typically simpler as it only involves content generation based on learned patterns.
- RAG: More complex as it integrates both retrieval and generation processes to enhance the quality of the output.
Application of RAG
RAG is applied in scenarios where generating accurate, contextually relevant, and up-to-date information is crucial. Here’s how RAG is typically applied:
- Question Answering Systems:
- Application: When a user asks a question, the system first retrieves relevant documents or information from a large database or the web. It then uses generative AI to craft a precise and coherent answer based on the retrieved content. RAG models achieve state-of-the-art results in open-domain QA; see Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
- Example: A customer support chatbot that answers user queries and pulls the latest information from product manuals or recent customer interactions.
- Content Generation with Context:
- Application: RAG can retrieve the most pertinent facts or data from various sources and generate a well-structured narrative for writing articles, reports, or summaries.
- Example: Automated news writing where the system retrieves the latest news reports or statistics and generates a comprehensive article.
- Personalized Recommendations:
- Application: RAG can pull relevant items or content based on the user’s history or preferences in recommendation systems and generate personalised recommendations or descriptions.
- Example: An e-commerce platform that retrieves similar products a user might be interested in and generates tailored product descriptions or suggestions.
- Document Completion or Expansion:
- Application: When working on a document, RAG can retrieve related information from other documents or databases to help complete sections or expand on ideas.
- Example: The system fetches relevant case law or references in legal or academic writing and generates detailed explanations or arguments.
- Translation and Localisation:
- Application: RAG can retrieve culturally or contextually appropriate phrases and then generate translations or localised content that better fits the target audience.
- Example: A translation tool that not only translates text but also pulls in relevant cultural references to create a more localised version of the content.
In these applications, RAG enhances the relevance and accuracy of the content generated by leveraging real-time contextual information. This makes it particularly valuable in dynamic environments where up-to-date information is essential.
Benefits and challenges
Claimed Benefits
Please note that the stated RAG benefits are yet to be assessed in respect to their particular applications and realisation deyails.
For instance, Legal AI tools are on the rise. However, they can still produce false information between 17% and 33% of the time, despite claims that methods like retrieval-augmented generation (RAG) eliminate errors, read in Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.
RAG systems have potential benefits that address generative AI shortcomings:
- Improved Accuracy and Relevance: By grounding the generative process in real-world data, RAG enhances the accuracy and relevance of the outputs.
- Enhanced Contextual Understanding: RAG leverages retrieved documents to provide contextually rich and coherent responses. We can feed RAG systems with essential documents to add context to the generative component.
- Reduced Hallucinations: By relying on factual data, RAG significantly reduces the instances of AI hallucinations. For instance, CustomGPT.AI offers a powerful approach to reducing AI hallucinations by leveraging domain-specific knowledge, high-quality data, and user feedback (read more in How To Stop ChatGPT From Making Things Up – The Hallucinations Problem).
Challenges and Considerations
Data quality, retrieval accuracy, and integration are all vital for the success of RAG systems, and each poses specific challenges that require careful management and optimisation.
Data Quality: The quality of the data used for retrieval is crucial in RAG systems. The generated content will reflect these flaws if the data sources are outdated, biased, or inaccurate.
For example, a healthcare RAG system generating treatment recommendations might pull data from an outdated medical database, leading to potentially harmful advice. Ensuring high-quality, reliable data sources is essential for effective RAG performance.
Retrieval Accuracy: Retrieval accuracy refers to the system’s ability to find the most relevant and precise information for a given query. The generative model may produce incorrect or irrelevant content if the retrieval component fails to select the correct or most relevant documents.
For instance, in a legal RAG system, inaccurate retrieval might pull in unrelated case law, leading to incorrect legal arguments or advice. Fine-tuning retrieval algorithms to prioritise relevance and precision is critical.
Integration Challenges: Integrating retrieval and generation components seamlessly is a significant challenge in RAG systems. The retrieval process must be fast and efficient, while the generative model needs to effectively use the retrieved information to produce coherent and contextually appropriate content.
For example, in a customer service chatbot, the system must quickly retrieve relevant product information and generate a response that feels natural and helpful to the user. Ensuring smooth integration involves addressing technical issues like latency, data formatting, and the alignment of retrieved content with the generative model’s capabilities.
Future Directions
Best Practices
Implementing the Retrieval and Generation (RAG) model effectively is essential for maximizing the quality and relevance of retrieved information and generated content. To achieve this, there are five key best practices to keep in mind:
-
Use High-Quality Data Sources: Ensure that you utilize reliable, up-to-date, and diverse data sources to enhance the accuracy and relevance of retrieved information. Regularly audit and update data repositories to maintain quality.
-
Optimize Retrieval Algorithms: Focus on improving retrieval accuracy by fine-tuning algorithms to prioritize relevance and context. Employ advanced search techniques, such as semantic search, to better match queries with appropriate content.
-
Streamline Integration: Ensure a seamless interaction between the retrieval and generation components. Optimize data pipelines for speed and efficiency and use techniques like fine-tuning and prompt engineering to align the retrieved content with the generative model’s capabilities.
-
Implement Feedback Loops: Continuously gather and incorporate user feedback into the system to improve retrieval accuracy and generation quality over time. This helps refine the model and address any performance gaps.
-
Monitor and Mitigate Bias: Regularly check for and mitigate any biases in retrieved data and generated content. Use diverse data sources and employ fairness techniques to ensure the system produces balanced and fair outputs.
These best practices will help you effectively implement the RAG model and maximize the quality and relevance of the retrieved information and generated content.
Emerging Trends in RAG
The emerging Trends and application examples in RAG include:
- Integration with Large Language Models (LLMs):
- Trend: As large language models (LLMs) like GPT-4 evolve, integrating them with advanced retrieval systems is becoming more common. This trend allows for generating more accurate and contextually rich content by leveraging the vast knowledge base of LLMs alongside real-time information retrieval.
- Example: Enhanced chatbots and virtual assistants that can pull in specific, up-to-date information from databases or the web while maintaining the conversational fluency of an LLM.
- Real-Time Data Retrieval:
- Trend: The move toward real-time or near-real-time data retrieval in RAG systems is gaining momentum. This allows for generating content that reflects the most current information available, making RAG systems highly valuable in dynamic fields like finance, news, and healthcare.
- Example: News summarisation tools that can retrieve the latest updates on an ongoing event and generate concise summaries in real-time.
- Personalisation and Contextualisation:
- Trend: There is a growing focus on using RAG systems to provide highly personalised and contextually aware content. By leveraging user-specific data during retrieval, these systems can generate content tailored to individual needs and preferences.
- Example: Personalised learning platforms that retrieve relevant educational materials and generate study guides based on a student’s unique learning history and current progress.
- Cross-Domain Applications:
- Trend: RAG is being applied across multiple domains, combining information from diverse fields to generate interdisciplinary insights. This trend is particularly useful in complex scenarios like healthcare, where combining medical, lifestyle, and environmental data can lead to more comprehensive recommendations.
- Example: A healthcare application that retrieves data from medical records, lifestyle surveys, and environmental factors to generate personalised health plans.
- Explainability and Transparency:
- Trend: As RAG systems become more sophisticated, there is a rising demand for explainability and transparency in retrieving and generating content. This includes developing systems explaining their information sources and the reasoning behind their outputs.
- Example: A legal RAG system that not only generates legal documents but also provides a transparent explanation of the sources used and how legal precedents were applied in the reasoning process.
In my post Explainable AI is possible, I argue that black-box-approach is oversimplification of how AI systems work and that it is indeed possible creating transparent and explainable AI programs.
- Enhanced Multimodal Capabilities:
- Trend: Emerging RAG systems are increasingly capable of handling and integrating multiple data modalities (e.g., text, images, audio). This allows for richer, more nuanced content generation from diverse data types.
- Example: A creative tool retrieving textual and visual content to generate comprehensive multimedia presentations or design concepts.
- Scalability and Efficiency Improvements:
- Trend: Efforts are being made to improve RAG systems’ scalability and efficiency, particularly in managing large-scale data retrieval and reducing latency in real-time applications. This involves optimising infrastructure and algorithms for larger datasets and faster retrieval times.
- Example: Enterprise-level RAG systems that can quickly retrieve and process vast amounts of data across global operations, enabling more efficient decision-making and content generation.
These trends indicate a rapid evolution of RAG systems, emphasising real-time capabilities, personalisation, cross-domain functionality, and transparency. These trends are shaping the future of intelligent content generation.
Research Opportunities
RAG (Retrieval-Augmented Generation) is a rapidly evolving field, with numerous opportunities for research to enhance its capabilities, address current limitations, and explore new applications. Below are key research opportunities and references to relevant papers that can be accessed through Google Scholar.
- Improving Retrieval Accuracy:
- Opportunity: Research can focus on developing more sophisticated retrieval algorithms that better understand context, semantics, and user intent. This includes exploring advanced neural retrieval models and integrating them with traditional search techniques to improve precision and recall.
- You can read the most recent paper that focuses on “Evaluating Retrieval Quality in Retrieval-Augmented Generation” by Alireza Salemi and Hamed Zamani (2024). The authors propose a novel evaluation approach, eRAG, where each document in the retrieval list is individually utilised by the large language model within the RAG system. The output generated for each document is then evaluated based on the downstream task ground truth labels. In this manner, the downstream performance for each document serves as its relevance label.
- Scalability and Efficiency:
- Opportunity: As RAG systems are applied to larger datasets and real-time applications, research is needed to scale these systems efficiently. This includes exploring distributed computing, indexing techniques, and low-latency retrieval mechanisms.
- “Dense Passage Retrieval for Open-Domain Question Answering” by Karpukhin et al. (2020). Open-domain question answering can be improved using dense representations for passage retrieval. This method outperforms traditional sparse vector space models by 9%-19% in top-20 passage retrieval accuracy and helps achieve new state-of-the-art results in open-domain QA benchmarks. This paper presents methods for efficient retrieval, which is crucial for scaling RAG systems.
- Multimodal Retrieval and Generation:
- Opportunity: There is significant potential in exploring how RAG systems can handle and integrate multiple data modalities, such as text, images, and audio, to generate richer, more comprehensive content.
- “Unifying vision-and-language tasks via text generation” by Cho et al. (2021). This work proposes a unified framework for vision-and-language learning, which learns different tasks in a single architecture with the same language modeling objective. The approach performs comparable to recent task-specific state-of-the-art vision-and-language models on popular benchmarks and shows better generalisation ability on rare-answered questions. The framework also allows multi-task learning in a single architecture with a single set of parameters, achieving similar performance to separately optimised single-task models. The code is publicly available at https://github.com/j-min/VL-T5. This research opens the door to exploring multimodal RAG systems.
- Personalisation and Adaptive Systems:
- Opportunity: Developing personalised RAG systems that adapt to individual user preferences and contexts is a promising area. Research can explore adaptive retrieval methods and context-aware generation techniques.
- “Design and Implementation of an Interactive Question-Answering System with Retrieval-Augmented Generation for Personalized Databases” by Byun et al. (2024). The paper discusses designing and implementing an interactive question-answering system with retrieval-augmented generation for personalised databases. It discusses integrating large language models with personalised data to enhance search precision and relevance. The study used GPT-3.5 and text-embedding-ada-002 models and evaluated the approach’s effectiveness. The results indicate that the combination of GPT-3.5 and text-embedding-ada-002 is effective for a personalised database question-answering system, with the potential for various language models depending on the application.
- Bias Mitigation and Fairness:
- Opportunity: Ensuring fairness and mitigating biases in RAG systems is a critical research area. This involves developing methods to detect, quantify, and reduce biases in retrieval and generation components.
- “FairRAG: Fair Human Generation via Fair Retrieval Augmentation” by Shrestha et al. (2024). Existing text-to-image generative models often reflect societal biases ingrained in their training data, leading to bias against certain demographic groups. In response, we introduce Fair Retrieval Augmented Generation (FairRAG), a framework that conditions pre-trained generative models on reference images from an external database to improve fairness in human image generation. FairRAG enhances fairness by providing images from diverse demographic groups during the generative process, outperforming existing methods regarding demographic diversity, image-text alignment, and image fidelity.
- Explainability and Transparency:
- Opportunity: As RAG systems become more integrated into decision-making processes, research on making these systems more explainable and transparent is essential. This includes developing techniques for tracing retrieved information sources and explaining how it is used in generation.
- “RAG-based Explainable Prediction of Road Users Behaviors for Automated Driving using Knowledge Graphs and Large Language Models” by Hussien et al. (2024). Predicting road users’ behaviours in the context of autonomous driving has been a focus of recent scientific attention. The authors propose integrating Knowledge Graphs and Large Language Models to accurately predict road users’ behaviours. This system has shown promising results in predicting pedestrians’ crossing actions and lane change manoeuvres.
- Cross-Domain Knowledge Integration:
- Opportunity: There is potential in researching how RAG systems can effectively integrate and utilise cross-domain knowledge to generate content that draws on multiple fields, leading to more interdisciplinary insights.
- “Leveraging Multi-AI Agents for Cross-Domain Knowledge Discovery” by Aryal et al. (2024). The authors are developing a new approach to knowledge discovery using multiple specialised AI agents. These agents collaborate to provide comprehensive insights that go beyond single-domain expertise. We have conducted experiments demonstrating the effectiveness of this approach in identifying and bridging knowledge gaps. The main goal is to enhance knowledge discovery and decision-making by leveraging each agent’s unique strengths and perspectives. The authors plan to custom-train the agents with more data to improve performance.
These research opportunities offer a pathway to advancing the field of RAG, addressing current challenges, and unlocking new applications. Each referenced paper provides a foundation for exploring these areas further, and they can be accessed through Google Scholar for more in-depth study.
Conclusion
Retrieval-augmented generation (RAG) combines retrieval-based and generative approaches in AI to enhance the quality and relevance of generated content while offering several key benefits:
- Enhanced Accuracy: RAG systems produce more accurate and contextually relevant responses by retrieving up-to-date and relevant information before generating content.
- Customisation: RAG systems can be fine-tuned to specific domains, allowing for tailored content generation that meets unique business needs.
- Scalability: RAG systems can efficiently handle large volumes of data, making them suitable for applications in dynamic and data-rich environments.
The future of RAG is promising, with emerging trends such as real-time data retrieval, multimodal content generation, and increased personalisation. As RAG systems evolve, they will become even more integral in customer support, content creation, and personalised recommendations, driving innovation and efficiency across industries. Enhanced explainability and bias mitigation will also expand RAG’s applicability in critical decision-making processes.
In my next post, I will write about RAG implementations.
Subscribe so you do not miss the new posts!
Try the following fantastic AI-powered applications.
I am affiliated with some of them (to support my blogging at no cost to you). I have also tried these apps myself, and I liked them.
Chatbase provides AI chatbots integration into websites.
Flot.AI assists in writing, improving, paraphrasing, summarizing, explaining, and translating your text.
CustomGPT.AI is a very accurate Retrieval-Augmented Generation tool that provides accurate answers using the latest ChatGPT to tackle the AI hallucination problem.
MindStudio.AI builds custom AI applications and automations without coding. Use the latest models from OpenAI, Anthropic, Google, Mistral, Meta, and more.
Originality.AI is very effecient plagiarism and AI content detection tool.
Did you like this post? Please let me know if you have any comments or suggestions.
Posts about AI that might be interesting for youReferences
2. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
3. Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools
5. How To Stop ChatGPT From Making Things Up – The Hallucinations Problem
7. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
9. Evaluating Retrieval Quality in Retrieval-Augmented Generation
10. Dense Passage Retrieval for Open-Domain Question Answering
11. Unifying vision-and-language tasks via text generation
13. FairRAG: Fair Human Generation via Fair Retrieval Augmentation
15. Leveraging Multi-AI Agents for Cross-Domain Knowledge Discovery
