
What Are Artificial Neural Networks (ANNs)?
Artificial neural networks (ANNs) are machine learning models composed of interconnected artificial neurons that map inputs to outputs through weighted connections and activation functions. ANNs are the cornerstone of Deep Learning algorithms. In this post, I briefly explain ANNs, their high-level structure, and their parameters.
How Artificial Neural Networks Simulate Biological Neurons
The name “Neural Networks” and their architecture are adopted from the human brain’s neural network. ANNs are designed to simulate human reasoning based on how neurons communicate. ANNs contain a set of artificial neurons connected.
In the picture below, we see the biological and artificial neurons. The artificial neuron is very simplified, and it consists of inputs, which are similar to dendrites in the biological neuron. Each input connection has an assigned weight, and both values are used to calculate the sum value. The weights define the importance of any given variable, and variables with larger weights contribute more to forming the output value. The activation function takes the sum of weighted inputs and forms the output Y. When the Y node is activated (or exceeds a threshold), it sends the output value to the next layer of the ANN.
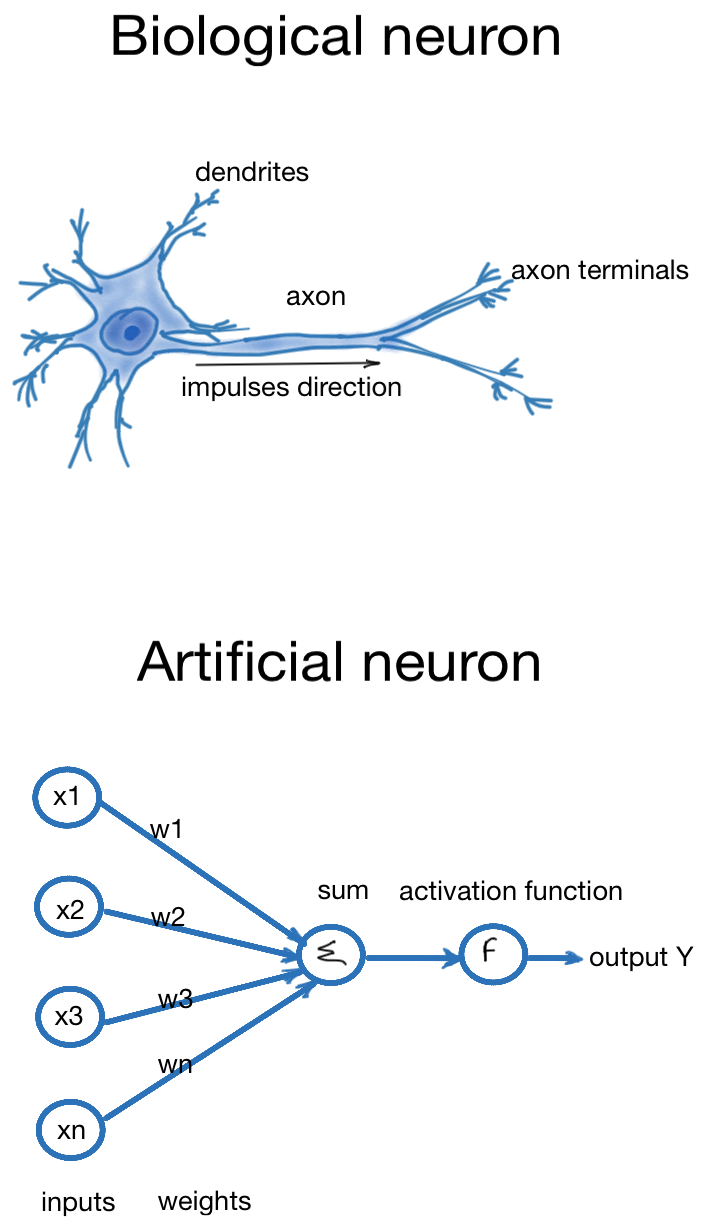
Artificial Neuron Parameters: Inputs, Weights, and Bias
As we see from the artificial neuron picture above, the neuron takes in n-inputs x1, x2, .., and xn. These input values, called features, are multiplied with respective weights w1, w2, .., and wn, and further summed up with bias. The weights w1.. wn can be initialised with random values. To create a well-performing neural network, we adjust weights using optimisation algorithms such as Gradient Descent. The main goal is to reduce error or loss function.
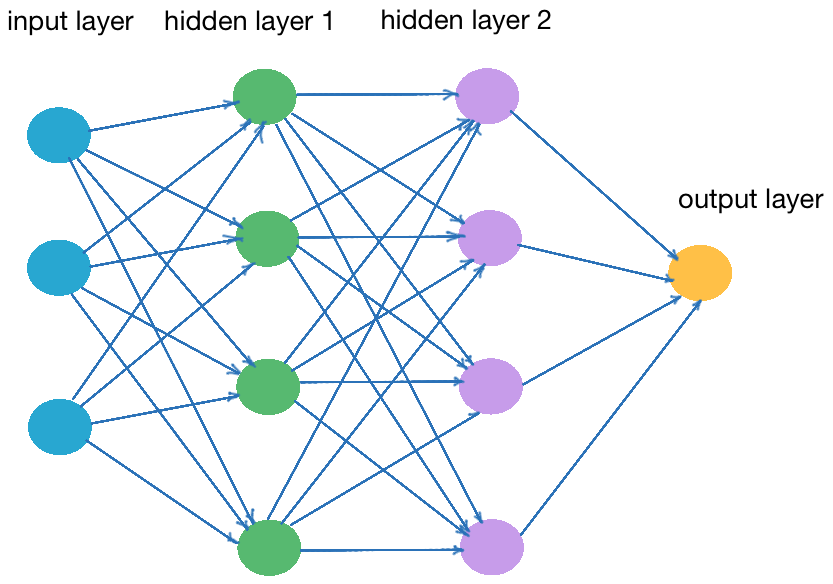
Multilayer ANNs: Input, Hidden, and Output Layers
Multilayer ANNs are created from one input, one or more hidden, and one output layer. The figure below shows a multilayer ANN with two hidden layers. Each of the colored cycles is a neuron, and we have four neutrons in each hidden layer.
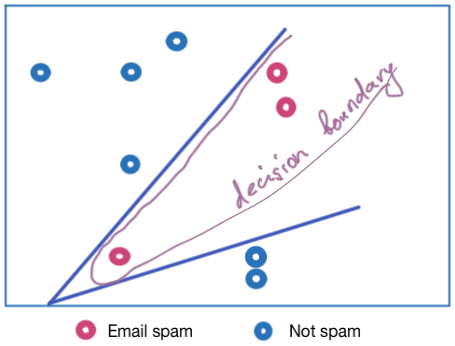
Why do we need hidden layers in ANNs? Hidden layers are required when we have non-linear data, for instance, in the prediction task, classes cannot be separated linearly. For instance, in a spam - not spam classification problem, we might have a dataset depicted below. As we see, the decision boundary to separate two classes can be enclosed by two lines, which essentially are linear regressions or two neurons. Therefore, we set two neurons in one hidden layer further connected with the output neuron.
Neuron Activation Functions: ReLU, Tanh, and Sigmoid
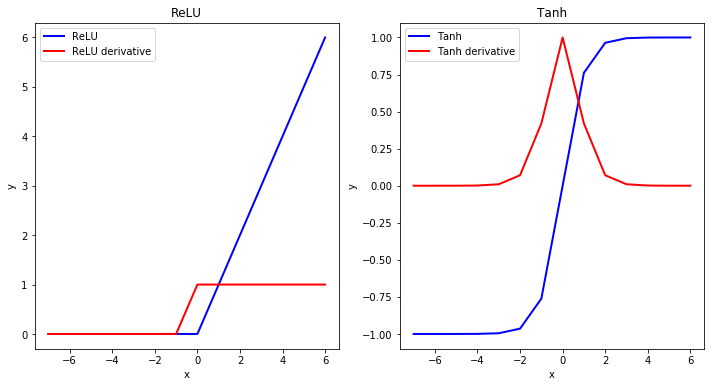
The output result Y will depend mainly on the activation function F. An activation function is a non-linear transformation applied to a neuron’s weighted input sum that determines the neuron’s output and lets the network model non-linear relationships. There are several options for the activation functions, including the Rectified Linear Activation function (ReLU), Hyperbolic Tangent (Tanh), or Sigmoid Activation function (see the Keras activations documentation). The choice depends on the problem, and we might compare results using different experiment activation functions. The most used by default, most straightforward, and addressing the vanishing gradient problem such as present in Tanh function, ReLU activation function is also easy to compute as max(0.0, x), wherein x is the result of summation on the previous step.
The figure below demonstrates the vanishing gradient problem in the Tanh function compared to the ReLU. As we see from the ReLU function, its derivative at values x<0 equals 0. Note that we consider that the derivative at x=0 equals 1. The derivative at x>0 equals 1. In contrast, Tanh’s derivative gives values of 0 at a broader range of values. This demonstrates the vanishing gradient situation when the derivative becomes small, and it is harder to train the ANN. This situation is particularly challenging in large ANNs, wherein very small derivatives are multiplied for all layers.
# Example plots for the tanh and ReLU activation functions
from math import exp
from matplotlib import pyplot
# tanh activation function with derivative
def tanh(input):
output = (exp(input) - exp(-input)) / (exp(input) + exp(-input))
d = 1-output**2
return output, d
# The relu activation function and its derivative
def relu(input):
output = max(0, input)
# Return the value just calculated with derivative
if input >= 0:
return(output), 1
else:
return(output), 0
inputs = [x for x in range(-7, 7)]
# calculate outputs for Tanh
outputs_tanh = [tanh(x)[0] for x in inputs]
outputs_tanh_derivative = [tanh(x)[1] for x in inputs]
# calculate outputs for ReLU
outputs_relu = [relu(x)[0] for x in inputs]
outputs_relu_derivative = [relu(x)[1] for x in inputs]
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
pyplot.plot(inputs, outputs_relu, label = "ReLU", color = "blue", linewidth = 2)
pyplot.plot(inputs, outputs_relu_derivative, label = "ReLU derivative", color = "red", linewidth = 2)
pyplot.legend()
plt.title("ReLU")
plt.xlabel('x')
plt.ylabel('y')
plt.subplot(1, 2, 2)
pyplot.plot(inputs, outputs_tanh, label = "Tanh", color = "blue", linewidth = 2)
pyplot.plot(inputs, outputs_tanh_derivative, label = "Tanh derivative", color = "red", linewidth = 2)
pyplot.legend()
plt.title("Tanh")
plt.xlabel('x')
plt.ylabel('y')
fig = plt.figure(figsize=(8, 6))
plt.show()
In his post How to Choose an Activation Function for Deep Learning, Jason Brownlee describes the general practice in choosing the activation function for hidden and output layers of ANNs. For selecting the activation function for hidden layers, ReLU activation function is helpful for network types of Multilayer Perceptron and Convolutional Neural Networks. In contrast, Recurrent Neural Networks can be used with Tanh or Sigmoid activation functions. The output layer’s activation function depends on the task we are solving. For instance, we can use Linear Activation with regression tasks, or SoftMax.
ANN Applications and Cloud Vision APIs
An artificial neural network is a layered, weight-based machine learning model that learns non-linear decision boundaries, which makes it the foundational architecture of modern deep learning. To sum up, ANNs allow the creation of robust algorithms for efficient classification and other artificial intelligence tasks. For instance, image recognition and classification of objects are applications of ANNs. Deep Neural Networks are particularly successful in problems such as face recognition or detecting abnormalities in medical images (Image Recognition with Deep Neural Networks and its Use Cases). At the moment, we can use out-of-box cloud-based machine learning solutions, for instance, Vision API for facial and natural landmarks detection, logos, and explicit content, and AutoML Vision by Google for image annotations (Image Recognition APIs: Google, Amazon, IBM, Microsoft, and more).
Did you like this post? Please let me know if you have any comments or suggestions.
Posts about Machine Learning that might be interesting for youArtificial Neural Network FAQ
Why use ReLU instead of Tanh or Sigmoid?
ReLU (max(0, x)) is the default activation for hidden layers because it is cheap to compute and avoids the vanishing gradient problem that affects Tanh and Sigmoid, whose derivatives shrink toward zero across a wide range of inputs. Small derivatives multiplied across many layers make deep networks hard to train, which is why ReLU is preferred for Multilayer Perceptrons and Convolutional Neural Networks.
Why do neural networks need hidden layers?
Hidden layers let an ANN model non-linear data where classes cannot be separated by a single straight line. Each hidden neuron learns part of a non-linear decision boundary; stacking them lets the network approximate complex functions that a single-layer model cannot.
What is the role of weights and bias in an artificial neuron?
Weights define the importance of each input: inputs with larger weights contribute more to the neuron’s output. The bias shifts the weighted sum before the activation function is applied, letting the neuron fire even when all inputs are zero. Training adjusts both with optimisation algorithms such as Gradient Descent to minimise the loss function.
What is the difference between an ANN and deep learning?
An artificial neural network is the model architecture (neurons, weights, layers). Deep learning is the practice of training ANNs with many hidden layers (“deep” networks). All deep learning uses ANNs, but a shallow one- or two-layer ANN is not usually called deep learning.
Related Reading
Enjoyed this? Get more like it.
Weekly notes on AI tools, Python, and what I'm actually building — plus a free copy of Fantastic AI: The 2026 Toolkit.
