
Fixing “Duplicate Without User-Selected Canonical” in Google Search Console
Today I received an email from the Google Search Console team informing me about an issue with my blog pages related to a “duplicate without user-selected canonical.” You know what? I did not have a duplicate webpage. Interestingly, my webpage was available with two protocols, HTTP and HTTPS; therefore, it was seen as having a duplicate! The problem was that I did not include a canonical definition for Google crawled to see this particular webpage as the only page to be crawled.
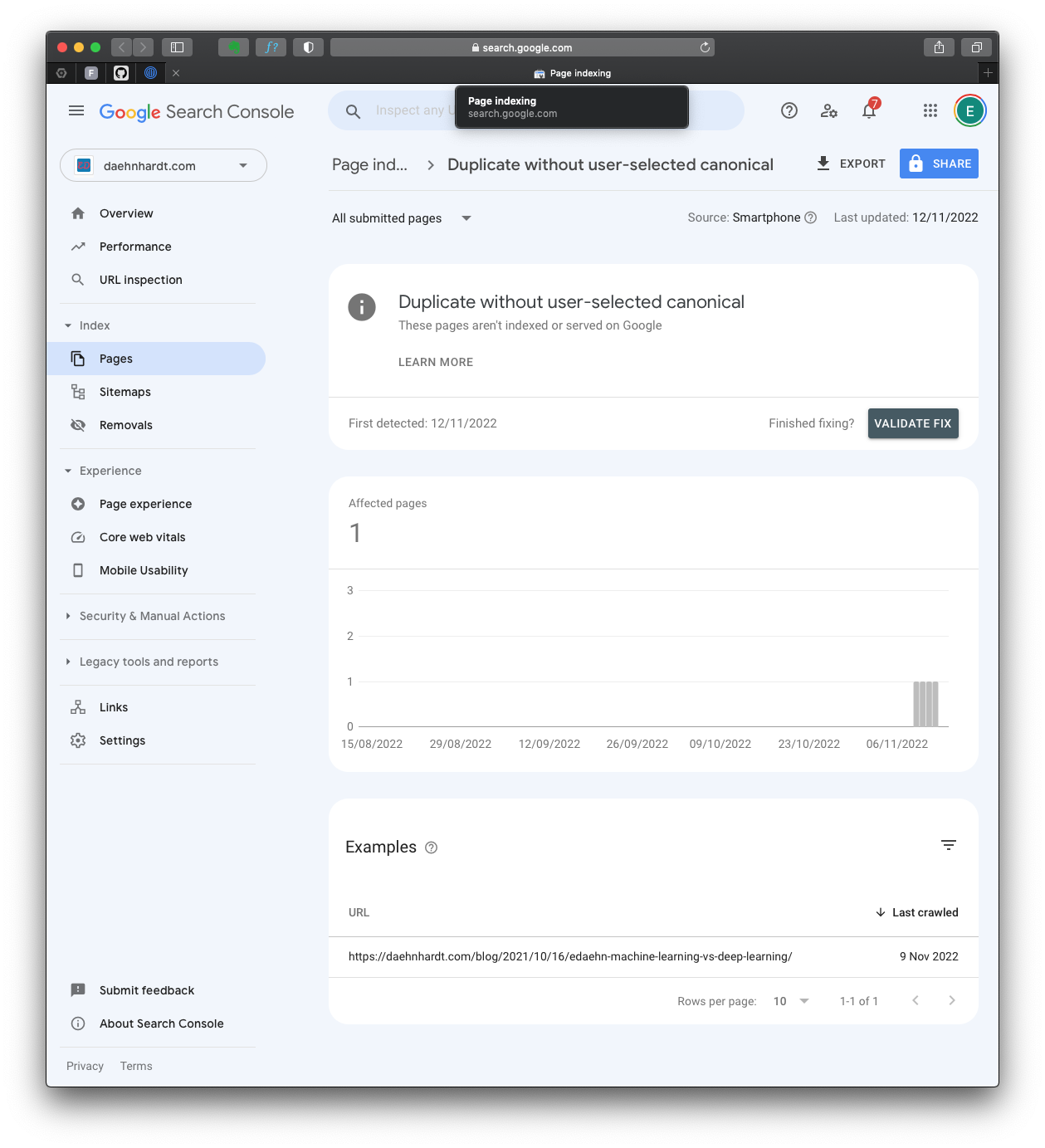
A duplicate without user-selected canonical
As a result, due to missed canonical definitions, my web blog failed to index correctly. What is canonical, and how can we start optimising webpages to make them “seen” by the Google search engine? Although getting noticed and promoting my blog was not really my first priority, my blog is still in development and is a kind of scrap-book of what I am doing, I was intrigued about making my blog more search engine friendly and seeing what happens next. Herein I describe all the steps performed to optimize my blog and the results I have got after being crawled by a Google search bot. Let’s go!
What is SEO (Search Engine Optimization)?
Search Engine Optimization (SEO) is the practice of formatting and structuring web pages so search engines index them correctly and rank them higher in search results. When we publish online, we generally expect to be found with search engines, and Google is the most prominent as of 2022, with its pros and cons discussed by Paul Gil in “The Best Search Engines of 2022.” When we want to make our website found, we specially format web pages to be sure that they are indexed well and further found by our readers. In simple terms, we define SEO as:
Search Engine Optimization helps to index web pages with search engines and potentially rank higher in search results.
Essential SEO Steps to Index a New Blog
Why did I put “potentially” in my SEO definition? I think that not all SEO activities might lead to better ranking and I want to focus mainly on the essential SEO steps.
1. Fixing Indexing Issues With Google Search Console
When we want to see whether our website is correctly indexed by Google and want to fix possible indexing or other issues, such as visibility of small text on mobile devices, we go to Google Search Console and check all pages, and why they are not indexed when some issues are found automatically.
Whoosh! I have 65 pages not indexed due to 6 reasons!
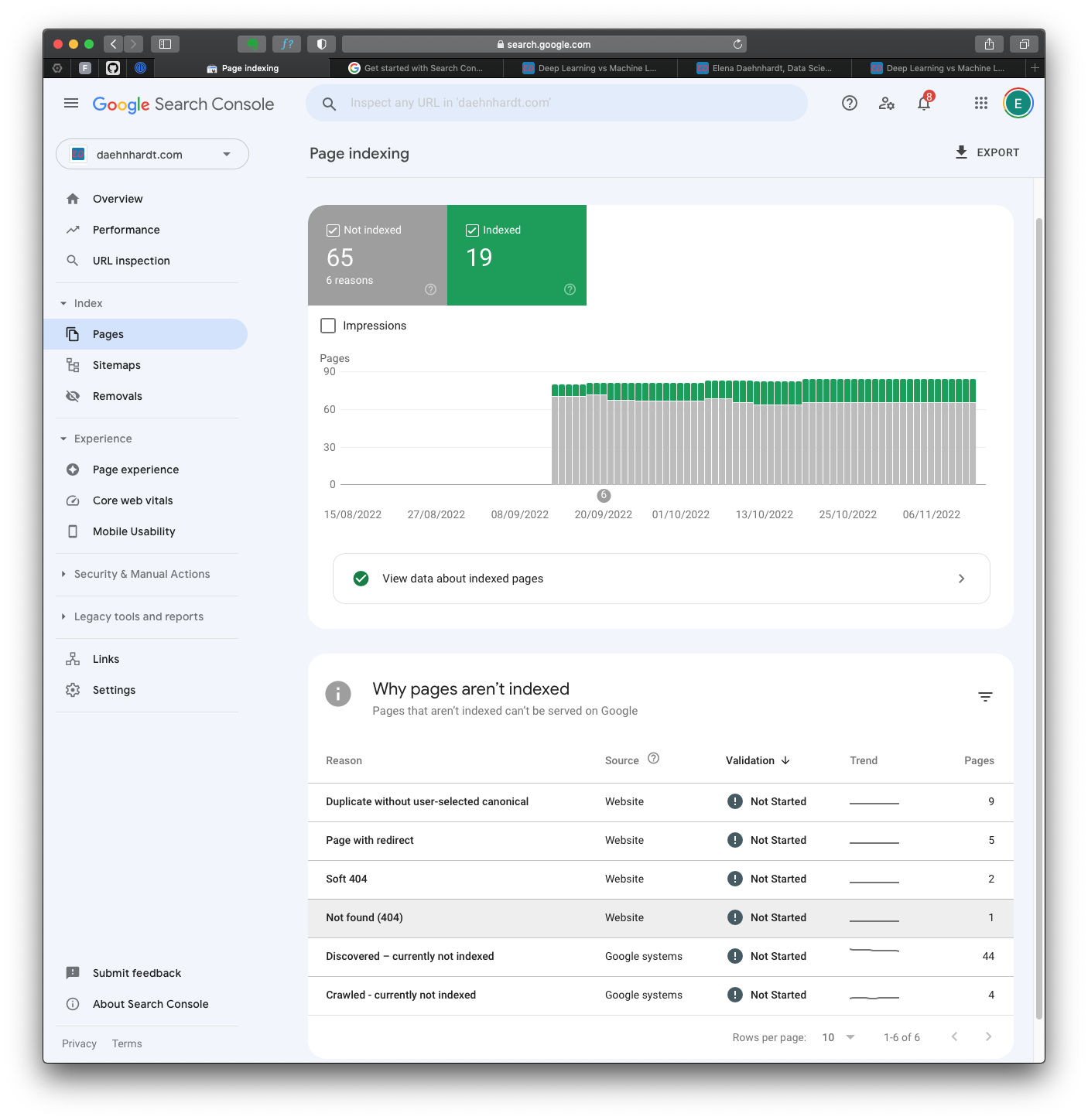
Page indexing in Google Search Console
Fixing Mobile Usability Errors With the Viewport Meta Tag
Furthermore, mobile usability needs to improve for my website. This could happen with too small font sizes, links located too close to each other, and the mobile viewport needs to be set.
I had large font sizes in my CSS file, so I looked at the problem. Adding the viewport tag solved the issue. That problem comes from the automatic scaling happening for some mobile devices, as pointed out in Tips for passing Google’s “Mobile Friendly” tests.
The solution is to add the following tag to your HTML header.
<meta name="viewport" content="width=device-width, initial-scale=1">
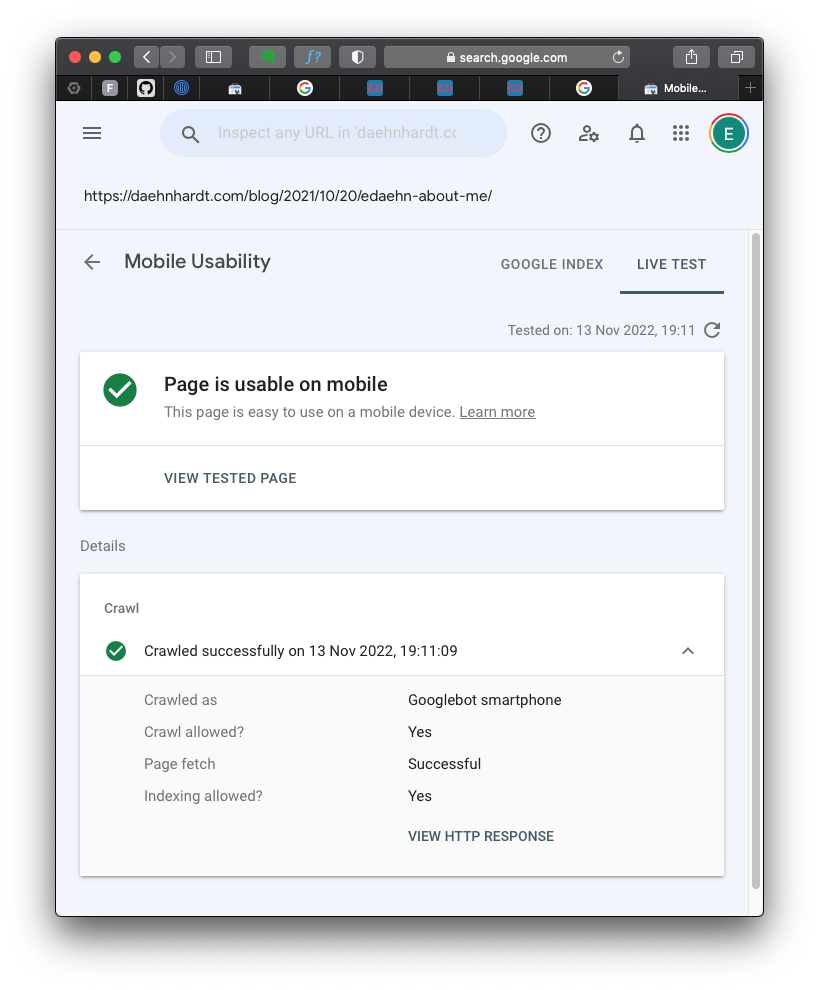
Mobile usability is passed
To confirm that your website is mobile-friendly, you can use a free tool provided by Google Search Console.
Canonical Tags: Resolving Duplicate Content
A canonical tag is an HTML <link rel="canonical"> element that tells search engines which URL is the authoritative version of a page when several URLs serve the same content. Canonization issues happen when the crawler is confused, and some of your webpages
are duplicates. As explained by Jean Abela in 2, you can fix the issue by explicitly marking the pages we want to
index, and this can be done via WordPress is the Yoast SEO plugin.
Alternatively, we can also fix the HTML headers to include a canonical tag
[2].
Simple, we include the canonical tags into webpage headers as follows:
<link rel="canonical" href="https://example.com/page" />
After updating our HTML with canonical tags, we tell Google crawler that we have fixed the issue using the Search Console [3].
And we request the page be re-indexed.
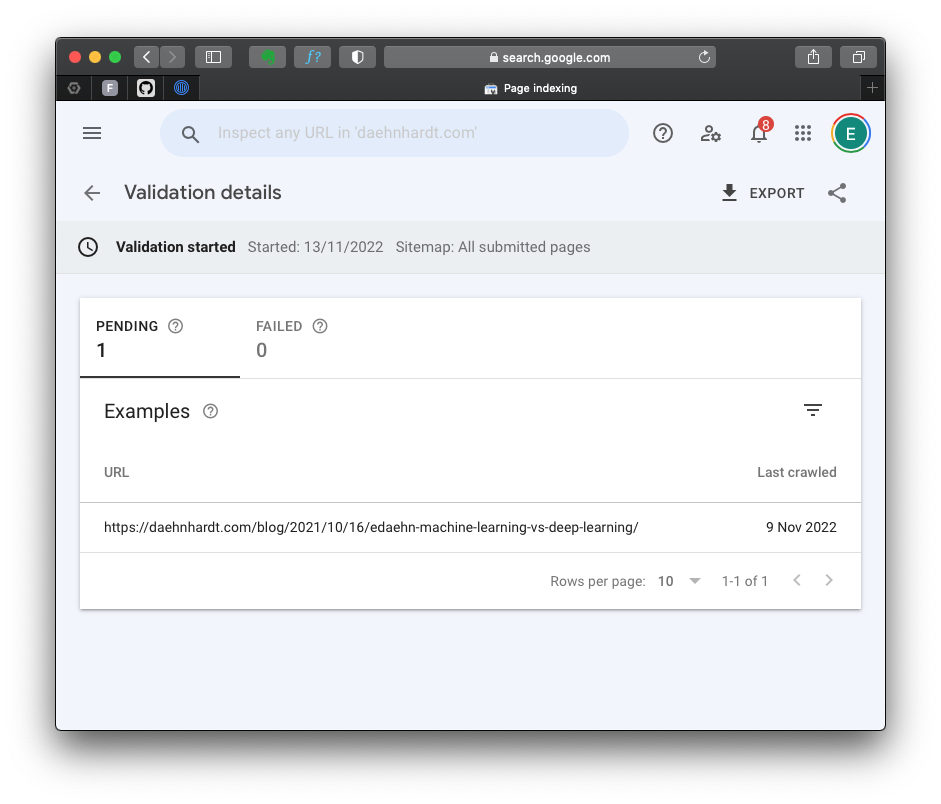
Pending validation of my fixed canonical issue
Pages With Redirect: Excluding Non-Indexable URLs
Since not all pages need to be indexed, I hand-pick only the required pages. For instance, I might not index some pages with redirects, such as my contact page.
2. Optimizing Title, Description, Headers, and Links
There is an opinion that keyword optimization is optional for modern search engines, which have become more intelligent. We cannot be sure about it, while we have yet to prove otherwise. There are keyword optimisation tools (consider ahrefs.com) still, in demand, free alternatives such as Ubersuggest are available.
Ubersuggest is a fantastic starting point for SEO of small blogs like mine. What do I really like the most? It automatically checks missing tags, links, and pages with duplicate title tags. The site speed was not critical for my blog since it is mostly text in Markdown. However, for more visual websites Ubersuggest might be more helpful.
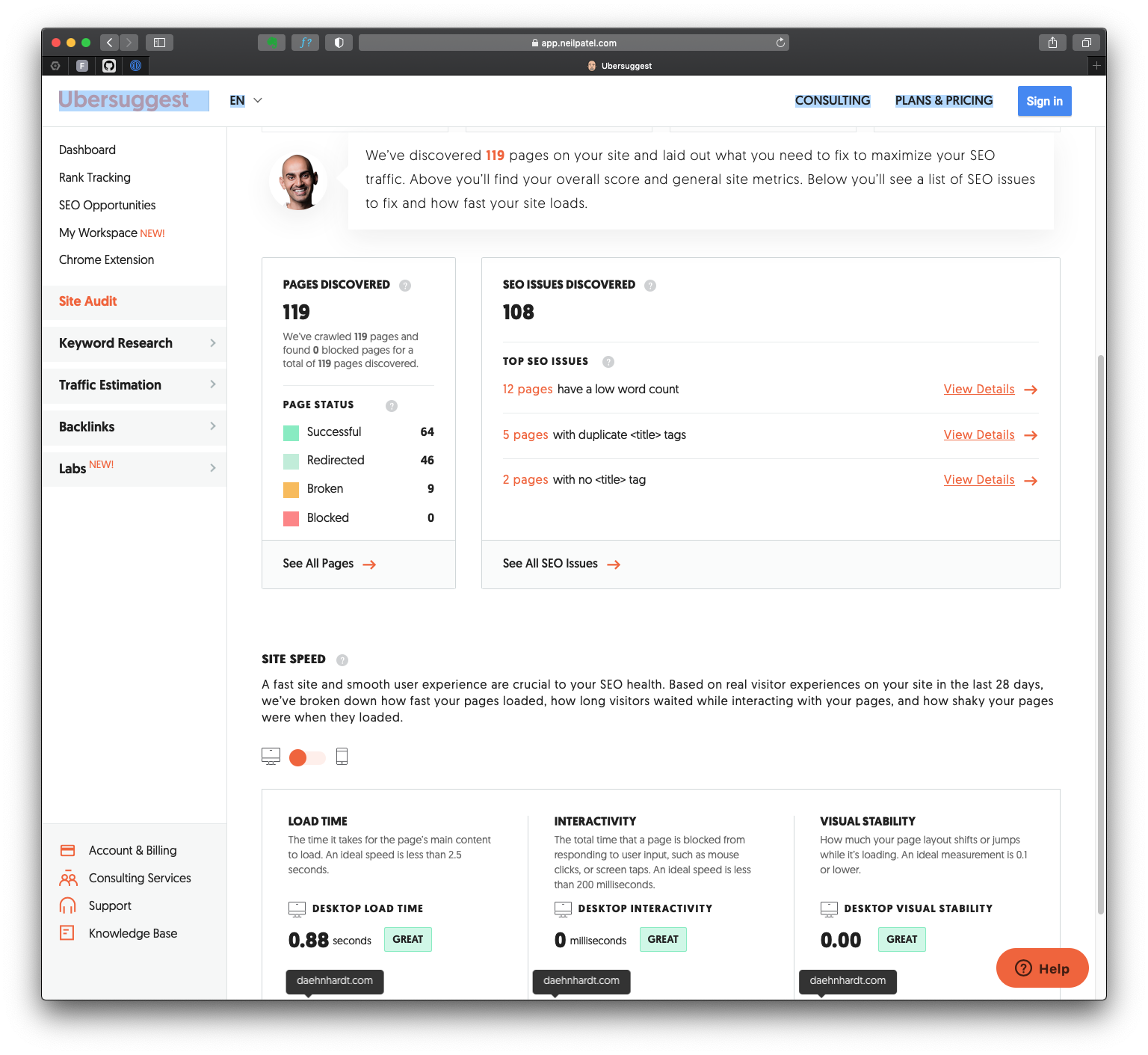
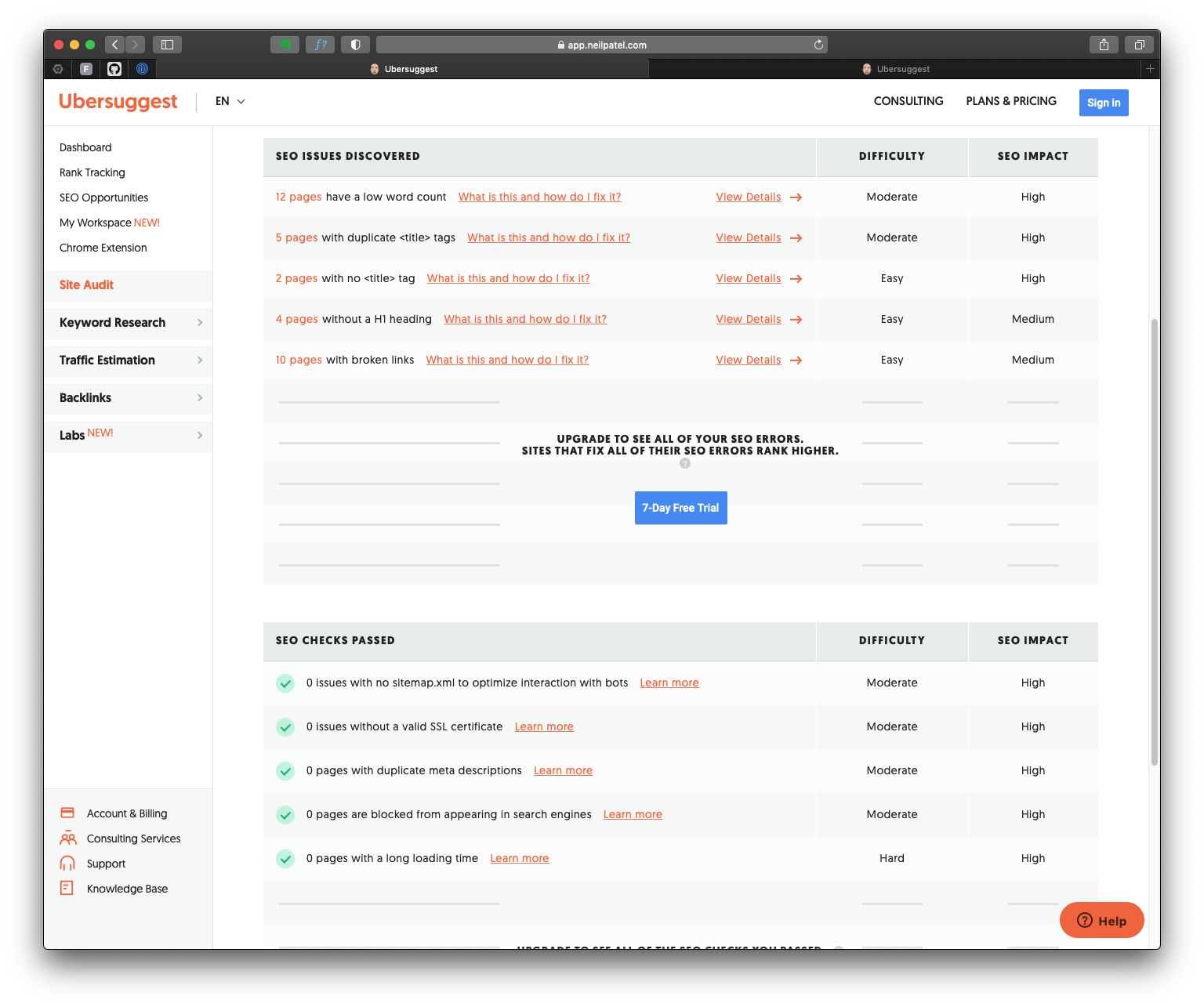
Ubersuggest tested my website
Another useful tool to analyse website performance is the PageSpeed Insights, which also provides information for desktop and mobile devices about accessibility, SEO and render-blocking resources.
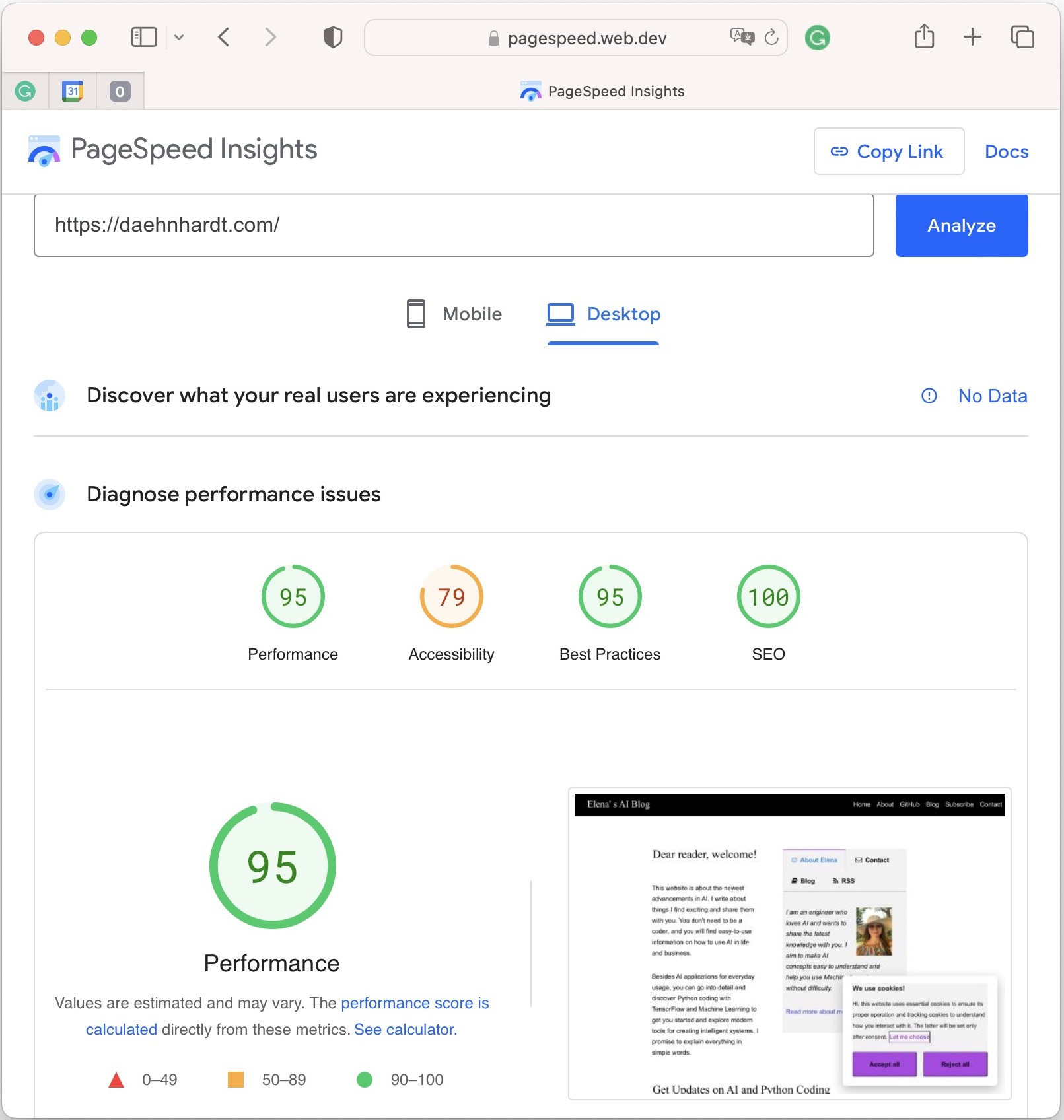
PageSpeed Insights
3. Choosing the Best Keywords for SEO
To optimise webpages for SEO, we define the keywords tag in HTML. The keywords can be defined within the meta tag:
<meta name= "keywords" content= "Python code examples">
A properly optimised page would have well-chosen keywords will let know search engines about your website topics and bring visitors with related searches. According to Stephen Hockman [8], keywords should be ideally included into:
- Surely, into the keywords and title meta tags of the page;
- Ideally, into content headers, preferably H1 and H2;
- Your page introduction;
- Page body content;
- The concluding section of your webpage;
- Images, into their filenames, ALT tags, titles;
- Classes for and <div> HTML elements;
- Titles defined for <p> HTML elements.
You can research keywords related to your webpage content with the help of tools like Google Keyword Planner, ahrefs.com, semrush.com (read their fantastic guide in [7]), Moz, etc., to find more popular keywords for your page. These tools can also help you understand the competition for the keywords and the search volume and trend. There is also a comparison of keywords research tools by Nathan Gotch in “We Tested 11 Keyword Research Services (Here’s the Top 3).”
In short, you need to know your best keywords based on your website content and purpose. What keywords are the most related to your webpage topic? What do you want to achieve with your webpage? What are your project objectives? The main goal of the keyword research is to find out which terms will bring good quality traffic that fits your target audience.
Should you need an automated tool for keyword research optimisation and other SEO tasks, outranking.io is an excellent SEO optimisation tool powered by AI to rank better in search results, improve organic reach, and avoid duplicate content penalties. As I have mentioned above, I am affiliated with and recommend outranking.io for “AI-assisted Workflow” that helps in SEO content writing.
You can also use Surfer SEO for comprehensive keyword research within your niche, providing high-potential keywords and content suggestions to enhance your Google ranking efforts. With Surfer AI, you can easily create SEO-optimized articles for Google ranking and revenue generation.
4. Building Quality Backlinks
The number of good-quality backlinks (links referring to your website) influences your ranking. The more is better. According to [10], we should aim to get links that have:
- Relevant content;
- High authority such as well-known media or with .edu/.gov domains;
- Good traffic;
- Good backlinks as well;
- Good outgoing links, which can be checked with Ahrefs Site Explorer;
- Been indexed on Google, which can be checked with: “site:example.com.”
5. Creating Sitemap.xml and Robots.txt for Crawler Control
Moreover, when we want to control which web pages are indexed by search engine crawlers and which are not, we create two simple files in the root directory of a website. Robots.txt is a plain-text file that tells search engine crawlers which pages or sections of a website should not be crawled or indexed. Sitemap.xml is an XML file that lists the URLs of a website, along with additional metadata about each URL (such as when it was last updated), to help search engines crawl the site more intelligently.
For instance, the contents of robots.txt may look something as follows:
User-agent: *
Crawl-delay: 10
Disallow: /private/
Sitemap: https://daehnhardt.com/sitemap.xml
This tells all web crawlers (indicated by the “*” in “User-agent: *”) to wait 10 seconds between requests when crawling the website. The “Disallow: /private/” directive tells crawlers not to access any pages within the “private” directory.
As we see, robots.txt can contain a reference to the sitemap.xml file.
<urlset xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9 http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd">
<url>
<loc>https://daehnhardt.com/tag/ai/</loc>
<changefreq>monthly</changefreq>
<priority>1.0</priority>
</url>
<url>
<loc>https://daehnhardt.com/tag/blogging/</loc>
<changefreq>monthly</changefreq>
<priority>1.0</priority>
</url>
</urlset>
The sitemap.xml lists all the pages on a website, along with metadata about each page. The purpose of a sitemap is to help search engines and other crawlers understand the structure of the website and the relationships between its pages. Sitemaps can include information such as the date a page was last updated, the frequency with which it changes, and its relative importance within the website. Sitemaps can also include information about images, videos and other multimedia content on the website. This information helps search engines crawl a site more intelligently and index its content more effectively. Sitemaps are beneficial for websites with a large number of pages or for websites that are difficult for search engines to crawl.
Sitemaps can be submitted to search engines through Webmaster Tools/Search Console for faster discovery and indexing. If you are interested in how I have created my sitemap, check my XML file for this blog.
Here are some best practices for creating a sitemap:
- Keep your sitemap up-to-date: Make sure to update your sitemap every time you make changes to your website, such as adding new pages or removing old ones.
- Use the correct XML format: Follow the guidelines set by the Sitemap protocol, which is the standard format for sitemaps.
- Use correct URL structure: Ensure all URLs in your sitemap are correct and follow a consistent structure. Avoid using URLs that redirect or have a “?” in them.
- Limit the number of URLs: Try to limit the number of URLs in your sitemap to 50,000 or fewer. If you have more URLs than that, you can create multiple sitemaps and submit them to search engines.
- Prioritize your pages: Use the
tag to indicate the relative importance of different pages on your website. - Include the last modified date: Use the
tag to indicate the last time a page was updated. This helps search engines determine which pages are more important to crawl. - Indicate the change frequency: Use the
tag to indicate how often a page is likely to change. This helps search engines to determine how often they should crawl a page.
6. Publishing High-Quality Content
Indeed, these activities will only work when our website has interesting, valuable, engaging content.
SEO and Indexing FAQ
What does “Duplicate without user-selected canonical” mean in Google Search Console?
It means Google found two or more URLs serving the same content and could not determine which one to index because no canonical URL was declared. A common cause is the same page being reachable over both HTTP and HTTPS. Fix it by adding <link rel="canonical" href="https://example.com/page" /> to the page <head>, then request re-indexing in Search Console.
How do I fix mobile usability errors in Google Search Console?
Add the viewport meta tag <meta name="viewport" content="width=device-width, initial-scale=1"> to your HTML <head>. This stops mobile browsers from auto-scaling the page and resolves errors caused by oversized fonts and links spaced too closely. Confirm the fix with Google’s Mobile-Friendly Test.
What is the difference between robots.txt and sitemap.xml?
robots.txt tells crawlers which paths they should not crawl (e.g. Disallow: /private/), while sitemap.xml lists the URLs you want crawled along with metadata such as lastmod, changefreq, and priority. The robots.txt file can reference the sitemap with a Sitemap: directive.
Do meta keywords still help SEO?
Google ignores the meta keywords tag for ranking, so it has little direct SEO value. Keyword research still matters, but the keywords belong in the title tag, headings (H1/H2), introduction, body, and image ALT text rather than a <meta name="keywords"> tag.
Conclusion: SEO Results After Fixing Indexing Issues
Search Engine Optimization is a maintenance process, not a one-time fix: correct canonical tags, a current sitemap, and mobile-friendly pages are the baseline that keeps a site indexable. I was “SEO-positive” in this post and hopefully helped people like me fix Google indexing issues. I have described a few steps to improve your website ranking. I will update this post about the SEO optimisation results later. Thanks for reading, and I will be happy to know your suggestions or comments. That’s all for today!

Did you like this post? Please let me know if you have any comments or suggestions.
Posts about building websites and SEO that might be interesting for youRelated tools you may want to try next.
Pictory.ai creates professional quality videos from your script with realistic AI voices, matching footage and music in a few clicks. Pictory.AI can also convert blog posts into captivating videos and extract highlights from your recordings to create branded video snippets for social media, and much more.
Play.ht can generate voice from text prompts, creates audio embeddings and play buttons for WordPress or any web page, podcast creation, and much more in respect to voice synthesis.
References
1. The Best Search Engines of 2022
2. Canonicalization Errors – How To Fix Duplicate Without User-Selected Canonical
3. Welcome to Google Search Console
4. Tips for passing Google’s “Mobile Friendly” tests
5. Ahrefs - SEO Tools & Resources To Grow Your Search Traffic
8. The Ultimate Keyword Research Guide for SEO
9. How to Add Keywords to a Website for SEO (20 Spots in HTML
10. Mobile-Friendly Test – Google Search Console
11. How to Get Backlinks Like an SEO Pro (NEW Guide for 2022)
15. We Tested 11 Keyword Research Services (Here’s the Top 3)
Enjoyed this? Get more like it.
Weekly notes on AI tools, Python, and what I'm actually building — plus a free copy of Fantastic AI: The 2026 Toolkit.
