
Nowadays, everyone talks about AI, chatGPT, and large language models. But what are they, and how are they different? In this post, we explore large language models and their relationship to Generative AI while briefly introducing their key techniques and related projects.
Introduction
Artificial Intelligence is a hot topic everyone discusses. Many terms, such as GenAI and Large Language Models (LLMs), are related but not the same. Sometimes, genAI and LLMs are used interchangeably. In this post, we explore the key differences and related projects.
Large Language Models vs. Generative AI
In short, LLMs are machine learning models trained on the immense text volume to generate text output. LLMs are a subset of generative AI, which is about many more file formats, such as images or music.
I like the following definitions:
Generative AI is like a master artist. It creates new things, whether text, images, music, or code. Generative AI is a versatile tool that can generate various forms of content.
Large Language Models (LLMs)** are a specific type of Generative AI focused on “understanding” and generating human language. LLMs learn from massive amounts of text data, enabling them to:
- Understand your requests: When you ask a question, LLMs decipher your intent.
- Generate text: They can write stories, poems, articles, and codes.
- Translate languages: LLMs can accurately translate between multiple languages.
- Summarize text: They can condense lengthy articles into concise summaries.
In short, Generative AI is a broader category encompassing various AI models that generate different types of content. LLMs are a subset focused solely on human language.
While both can generate content, LLMs excel at “understanding” and processing language, enabling more complex interactions like conversation and translation.
Did you notice that I have enclosed the “understanding” capability of LLMs in the apostrophes? Indeed, no model can understand the text as we humans do. Language models, even with intent or any other algorithm that generates output, are based primarily on probabilities and statistics.
Natural Language Processing (NLP) is a field that deals with text information. If you want to create your simple (small) language model as I did in 2022, read my post TensorFlow: Romancing with TensorFlow and NLP wherein I gently explain the whole process and write some Python code.
Key Algorithms and Projects
Generative AI and Large Language Models (LLMs) are fantastic AI techniques. But how do they work? Let’s explore the key algorithms and open-source projects that power these AI marvels.
Generative AI
Two of the most important algorithms for creating genAI applications include Generative Adversarial Networks and Variational Encoders.
Generative Adversarial Networks
Generative Adversarial Networks are two neural networks working together: a generator and a discriminator. The generator creates data while the discriminator evaluates its authenticity. This adversarial process refines the generator’s output, leading to the creation of highly realistic images, the generation of synthetic data, and the enhancement of image resolution.
The adversarial process in Generative Adversarial Networks (GANs) consists of two neural networks:
-
The Generator: This network acts like a counterfeiter, trying to create fake data that looks convincingly real. It takes random noise as input and transforms it into something resembling the real data it was trained on (e.g., images, text, music).
-
The Discriminator: This network is like a detective trying to distinguish between real data (from the training set) and fake data (produced by the generator). It learns to identify subtle features and patterns that give away the fakes.

Generative adversarial network, Zhang, Aston and Lipton, Zachary C. and Li, Mu and Smola, Alexander J., CC BY-SA 4.0, via Wikimedia Commons
Both networks learn from the discriminator’s feedback: * The discriminator gets better at spotting fakes. * The generator gets better at creating fakes that fool the discriminator.
This back-and-forth competition drives both networks to improve. The generator becomes increasingly skilled at producing realistic data, while the discriminator becomes more discerning. The process continues until the generator produces outputs indistinguishable from actual data, effectively fooling the discriminator.
The adversarial process makes GANs so powerful for generating realistic and creative content. It’s a key innovation in AI, enabling machines to learn and create in previously unimaginable ways.
Ian Goodfellow is credited with inventing Generative Adversarial Networks (GANs), introduced in a 2014 paper titled “Generative Adversarial Nets”, co-authored with other researchers. Goodfellow’s invention has profoundly impacted the field of AI, enabling the generation of incredibly realistic and creative content.
GANs are now used in a wide range of applications, including:
- Image generation: Creating realistic images of people, objects, and scenes.
- Style transfer: Transferring the artistic style of one image to another.
- Drug discovery: Generating new molecules with desired properties.
- Data augmentation: Creating synthetic data to improve the training of machine learning models.
Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) learn the underlying input data patterns to generate new, similar data points. They excel at capturing the essence of the data and producing variations.
Variational autoencoders, or VAEs for short, are deep learning models that have two main parts: an encoder and a decoder [4]. The encoder picks out the key latent variables from the training data, while the decoder uses those variables to rebuild the original input. VAEs are unique because they create a continuous, probabilistic representation of the latent space instead of a fixed one like most autoencoders. This means they can not only reconstruct the original input well but also generate new samples that look a lot like the original data [4].

Variational Autoencoder structure, EugenioT, CC BY-SA 4.0, via Wikimedia Commons
Diederik P. Kingma and Max Welling introduced variational autoencoders (VAEs) in 2013 in a paper titled “Auto-Encoding Variational Bayes”.
VAEs have since become popular for learning latent representations and generating new data. They are used in various applications, including:
- Image generation: Creating new images that resemble a given dataset.
- Anomaly detection: Identifying unusual data points that deviate from the norm.
- Representation learning: Learning meaningful data representations for downstream tasks.
Large Language Models (LLMs)
LLMs are a specialized type of Generative AI focused on human language. Trained on vast text data, they can understand, interpret, and generate human-like text.
According to the article “LLM Leaderboard - Comparison of GPT-4o, Llama 3, Mistral, Gemini and over 30 models ”, the best-performing and good-quality LLMs available today include:
- o1-preview (OpenAI): Introducing OpenAI o1-preview;
- Llama 3.1 405B (META): Introducing Llama 3.1: Our most capable models to date;
- Gemini 1.5 Pro (Sep) (Google): Gemini 1.5 Pro Now Available in 180+ Countries; with Native Audio Understanding, System Instructions, JSON Mode and more;
- Claude 3.5 Sonnet (Oct) (Antropic): Claude 3.5 Sonnet;
- Mistral Large 2 (Nov ‘24) (Mistral AI_): What Is Mistral Large 2? How It Works, Use Cases & More.
Please notice that many LLMs available today are multimodal (such as chatGPT-4o, where the “o” stands for omni—meaning “all”—because it can generate different types of content, such as text, images, video, and audio).
OpenAI gradually enables users to interact with the LLM using their voices or images. - read about these features in ChatGPT can now see, hear, and speak.
The fantastic new features highlighted in ChatGPT can now see, hear, and speak are:
- You can talk to ChatGPT, which will respond via voice on the mobile app (iOS and Android).
- You can show images to ChatGPT for analysis by tapping the photo button and highlighting parts of the image for discussion.
The voice and image features are powered by advanced models, including the new text-to-speech model and Whisper for speech recognition, and GPT-3.5 and GPT-4 to reason about images as well as text - ChatGPT can now see, hear, and speak.
Transformers
The Transformers’ architecture is the foundation of many LLMs. Transformers utilize “attention” mechanisms to weigh the significance of different words in a sentence, enabling them to grasp context and relationships within text.
Transformers help create powerful conversational AI, such as chatbots, translating languages, summarising text, and generating different text formats.
While it’s difficult to pinpoint a single “inventor” of the Transformer, the key innovation is attributed to a team of Google researchers. A 2017 paper titled “Attention Is All You Need” revolutionized the field of Natural Language Processing (NLP) by proposing a new neural network architecture that relied entirely on the attention mechanism. This differed significantly from previous approaches that relied heavily on recurrent or convolutional layers.

The transformer model architecture, Yuening Jia, CC BY-SA 3.0, via Wikimedia Commons
While the “Attention Is All You Need” paper is a landmark publication, it’s worth noting that other researchers had explored the concept of attention mechanisms earlier. However, this paper brought all the pieces together and demonstrated the power of attention-based models for various NLP tasks.
The Transformer architecture has since become the foundation for many state-of-the-art language models, including:
- BERT (Google): BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding;
- GPT (OpenAI): GPT-4 Technical Report (the most recent to date GPT model);
- LaMDA (Google): LaMDA: our breakthrough conversation technology
- Bard (Google): Try Bard and share your feedback
These models have achieved remarkable performance in various tasks, such as machine translation, text summarization, question answering, and text generation.
While Transformers have become the dominant architecture for large language models (LLMs), they have some limitations, particularly regarding computational cost and memory requirements for long sequences. This has led to the exploration of alternative algorithms.
The image below shows that GPT models are part of large language models, which are encompassed by Generative AI.
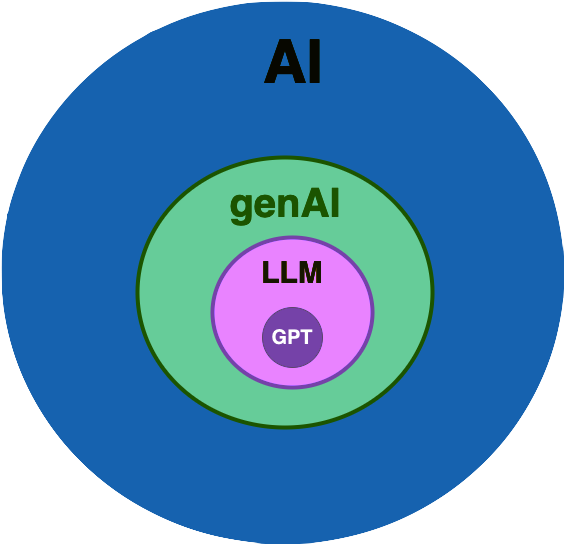
Generative AI, LLM and GPT
State Space Models (SSMs)
SSMs represent information as a set of hidden states that evolve. They can efficiently process sequential data by updating these states recursively. Recent advances in SSMs have shown they can achieve competitive performance with Transformers on various language tasks.
SSMs have many advantages. They typically scale linearly with sequence length, making them more efficient for processing long texts. Modern SSMs like Mamba have demonstrated impressive performance results in language modeling, surpassing comparable Transformers.
SSM Examples: * Mamba: Combines the recurrence of SSMs with the feedforward blocks of Transformers. It introduces a novel “selective state space” mechanism for efficient memory usage. * Hungry Hungry Hippos (H3): One of the first SSMs to achieve competitive performance with Transformers in language modeling. * Jamba: A hybrid architecture that combines Transformers with Mamba layers for improved efficiency and performance.

Block diagram of a typical state space representation with feedback, Cburnett, CC0, via Wikimedia Commons
SSMs have a rich history with contributions from various fields. While there’s no single inventor, Kalman’s work on the Kalman filter and the development of Hidden Markov Model are crucial milestones. Recent works such as Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality are great examples of further advancing SSMs, particularly in deep learning and language modeling.
Recurrent Neural Networks (RNNs)
Recurrent neural networks are designed for sequential data processing, allowing them to handle text, speech, and time series tasks. The key component is the recurrent unit, which updates a hidden state at each time step, enabling the learning of past information [9].
The long short-term memory (read Long Short-term Memory) architecture, introduced in 1997, addressed the vanishing gradient problem in early RNNs, enhancing their ability to learn long-range dependencies [9]. RNNs are widely used in handwriting recognition, speech recognition, natural language processing, and neural machine translation [9].
RNNs process sequential data by maintaining a hidden state that is updated at each step. This allows them to “remember” previous information and use it to influence their output.
RRNs are fantastic because they can process sequences of varying lengths, unlike some Transformer architectures. Besides, RNNs are generally simpler to understand and implement than Transformers.
The main challenge of RRNs is vanishing gradients. RNNs process sequences step-by-step, which can be slower than the parallel processing of Transformers.
What is the vanishing gradient? The vanishing gradient problem happens in neural networks when the gradients (used to update weights during training) become extremely small in early layers as they are backpropagated. This makes it hard for those layers to learn, slowing or halting progress in training. I have shown a simple example of the vanishing gradient in my post Artificial Neural Networks. Do you like a more in-depth explanation? - read the paper The Vanishing Gradient Problem During Learning Recurrent Neural Nets and Problem Solutions referred in my related post TensorFlow: Romancing with TensorFlow and NLP.
RRN Examples: * Long Short-Term Memory (LSTM): A type of RNN designed to address the vanishing gradient problem. * Gated Recurrent Unit (GRU): A simpler and more efficient variant of LSTM.
Convolutional Neural Networks (CNNs)
Convolutional neural networks use convolutional filters to extract features from data. While traditionally used for image processing, they can also be adapted for sequential data.
CNNs excel at capturing local patterns in data, which can be helpful in language tasks like identifying phrases or entities. CNNs can process input in parallel, leading to faster computation.
However, CNNs can struggle to capture long-range dependencies in sequences. To capture longer contexts, CNNs may need large receptive fields, which can increase computational cost.
CNN Examples: * ByteNet: A CNN-based architecture for machine translation that uses dilated convolutions to capture longer context. * WaveNet: A CNN-based model for generating realistic speech.

A 3 layer 1D CNN feed-forward diagram with kernel size of 3 and stride of 1., Vicente Oyanedel M., CC BY-SA 4.0 , via Wikimedia Commons
Would you like to create your own CNN with TensorFlow in Python? - Read my previous post TensorFlow: Convolutional Neural Networks for Image Classification.
Hybrid Approaches
Hybrid Approaches combine elements from different architectures, such as Transformers and SSMs, to leverage their strengths. This could achieve the best of both worlds when the efficiency of SSMs accompanied the expressive power of Transformers. For instance, Jamba: A Hybrid Transformer-Mamba Language Model combines Transformers with Mamba layers.
It’s important to note that the field of LLMs is constantly evolving, and new architectures are being continuously developed. While Transformers are dominant, these alternatives show promise and could lead to even more powerful and efficient language models.
Related GitHub projects
Several openly-available projects are driving advancements in Generative AI and LLMs, providing tools and resources for developers:
- Hugging Face Transformers: A popular library offering pre-trained Transformer models for various NLP tasks.
- PyTorch: A widely used deep learning framework with extensive support for building and training Generative AI models.
- TensorFlow: Another prominent deep learning framework offering tools for developing and deploying Generative AI models.
- OpenAI’s GPT-2: While GPT-3 is not open source, its predecessor, GPT-2, offers valuable insights into the development of LLMs.
- EleutherAI’s GPT-Neo: An open-source alternative to GPT-3, providing comparable performance on various tasks.
Suppose you are interested in the LLM research and elephants. In that case, I suggest reading the Suppressing Pink Elephants with Direct Principle Feedback, discussing limitations in current language models and presenting a method for giving feedback to these models.
Conclusion
In conclusion, while Generative AI and Large Language Models (LLMs) are often mentioned together, they serve distinct purposes within artificial intelligence. Generative AI covers a wide array of content creation, whereas LLMs specifically focus on language understanding and generation. Understanding their differences, fundamental techniques like Transformers and GANs, and exploring notable open-source projects can help enthusiasts and developers navigate these transformative technologies effectively. Now, we can also create our LLMs when having resources and an interest :)
Did you like this post? Please let me know if you have any comments or suggestions.
Posts about AI that might be interesting for youReferences
1. TensorFlow: Romancing with TensorFlow and NLP
3. Generative Adversarial Nets
4. What is a variational autoencoder?
5. Auto-Encoding Variational Bayes
7. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
9. LaMDA: our breakthrough conversation technology
10. Try Bard and share your feedback
11. LLM Leaderboard - Comparison of GPT-4o, Llama 3, Mistral, Gemini and over 30 models
12. Introducing OpenAI o1-preview
13. Introducing Llama 3.1: Our most capable models to date
16. What Is Mistral Large 2? How It Works, Use Cases & More
17. ChatGPT can now see, hear, and speak
23. Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
24. Tensors and Dynamic neural networks in Python with strong GPU acceleration
25. An Open Source Machine Learning Framework for Everyone
26. Code for the paper “Language Models are Unsupervised Multitask Learners”
28. Suppressing Pink Elephants with Direct Principle Feedback
